Jekyll2024-11-11T19:15:01-06:00https://mig8447.github.io/feed.xmlTales of a DeveloperA blog about mig8447's day to day learning in the world of software developmentMiguel Sánchez VillafánChanging the hostname in Ubuntu 18.042020-03-14T10:13:08-06:002020-03-14T10:13:08-06:00https://mig8447.github.io/linux/ubuntu/network/2020/03/14/changing-the-hostname-in-ubuntu-18.04This is a short post describing how to change the hostname in Ubuntu 18.04
TL;DR
Execute the following commands:
hostnamectl set-hostname <NEW_HOSTNAME>
service avahi-daemon restart
Replacing <NEW_HOSTNAME> with the new name you want for your host.
The situation
I installed Ubuntu 18.04 in an old machine I had and it was working but then I
decided I had picked the wrong hostname at install time and wanted to change it.
I read several posts on how to do it and it turns out that since Ubuntu 16.04,
there's a command line utility called hostnamectl that saves you the hassle of
editing files under the /etc directory, which is nice BUT, there was one thing
missing.
Once I changed the hostname (See the TL;DR section above) I
disconnected from SSH and tried to connect using <NEW_HOSTNAME>.local, and it
didn't work. Notice that these hostnames are part of the Zero-Configuration
Networking protocol (AKA Bonjour) which in Ubuntu (And also in other OSes I
guess, although I can't confirm right now) is used by a program/service
called avahi which comes pre-installed (That's why I could use
<OLD_HOSTNAME>.local in the first place). Turns out that if you change the
hostname, you have to restart the avahi service for it to take the new
hostname. Once that was done, I could connect to <NEW_HOSTNAME>.local without
any issues.
]]>Miguel Sánchez VillafánFlatCAM beta 8.96 installation in macOS Mojave 10.142020-03-13T12:49:29-06:002020-03-13T12:49:29-06:00https://mig8447.github.io/manufacturing/electronics/flatcam/2020/03/13/flatcam-beta-8.96-installation-in-macos-mojave-10.14This post intends to be a guide to install FlatCAM 8.86 in macOS Mojave 10.14
My experience
I spent around 6 hours trying to install FlatCAM. I used the provided instructions in the FlatCAM Manual - OSX Installation document without success. Turns out that the instructions in that page are crafted for macOS Sierra, whose release date was back in 2016. Homebrew, which is the recommended tool to install the dependencies upgrades frequently and with such updates in Jan 1st of 2020, it removed Python 2 and any of its related libraries due to Python 2 End of Life. This made it difficult to get FlatCAM installed because version 8.5 is based in Python 2. After a few hours trying to force the installation of old packages in Homebrew I found the macOS installation no longer possible issue in their repository which stated that version 8.96 did support Python 3 and PyQT5 which are the versions currently (As of March 13 2020) installed by Homebrew so I decided to give it a try and came up with the following list of commands to execute.
Installation process
Note that lines starting with # are comments and are not meant to be pasted in the terminal but for clarity to the reader
# Go to our Downloads foldercd ~/Downloads
# Update Homebrew packages' list
brew update
# Install FlatCAM depencencies Python3, PyQT5, gets and spatialindex
brew install python pyqt geos spatialindex
# Install Python 3's virtualenv. This is useful not to pollute our global libraries directory
pip3 install virtualenv
# Download FlatCAM 8.96, currently in beta
wget https://bitbucket.org/jpcgt/flatcam/downloads/FlatCAM_beta_8.96_sources.zip
# Unarchive the files
unzip FlatCAM_beta_8.96_sources.zip
# Change to the FlatCAM directorycd FlatCAM_beta_8.96_sources
# Create a Python virtual environment
virtualenv env# Activate the virtual environmentsource env/bin/activate
# Install all Python dependencies in the virtual environment
pip3 install numpy matplotlib rtree scipy shapely simplejson lxml rasterio ezdxf svg.path freetype-py fontTools ortools vispy PyOpenGL PyQT5
# Get out of the virtual environment
deactivate
# Create a script to execute FlatCAMcat<<'EOF' > FlatCAM
#!/bin/bash
# Make sure the Homebrew executable paths are in the PATH env variable
export PATH='/usr/local/bin:/usr/local/sbin:'"$PATH"
# Find the script's real path
script_directory="$(cd"$(dirname"${BASH_SOURCE[0]}")"&&pwd)"
if real_script_path="$(readlink"$script_directory/$(basename"$0")")"
then
real_script_directory="$(dirname"$real_script_path")"
else
# shellcheck disable=SC2034
real_script_directory="$script_directory"
fi
exit_code=0
# Enable FlatCAM's virtual env
source "$script_directory"'/env/bin/activate'
# Execute FlatCAM, log the output to FlatCAM.log
python3 "$script_directory"'/FlatCAM.py' &> "$script_directory"'/FlatCAM.log'
# Capture the exit code
exit_code="$?"
# Disable the virtual env
deactivate
# Exit the script with the exit code returned by FlatCAM
exit "$exit_code"
EOF
# Create an AppleScript to execute the script we just createdcat<<'EOF' > FlatCAM.scpt
set script_path to POSIX path of ((path to me as text) & "::") & "FlatCAM"
do shell script script_path
EOF
# Compile the AppleScript into an application
osacompile -o FlatCAM.app FlatCAM.scpt
# Move up one directory (Back to ~/Downloads)cd ..
# Move the application folder to the computer's Applicationsmv FlatCAM_beta_8.96_sources /Applications/FlatCAM_beta_8.96
# Open the application from the terminal (This is not needed, you can open it double clicking the file in the Applications folder)
open /Applications/FlatCAM_beta_8.96/FlatCAM.app
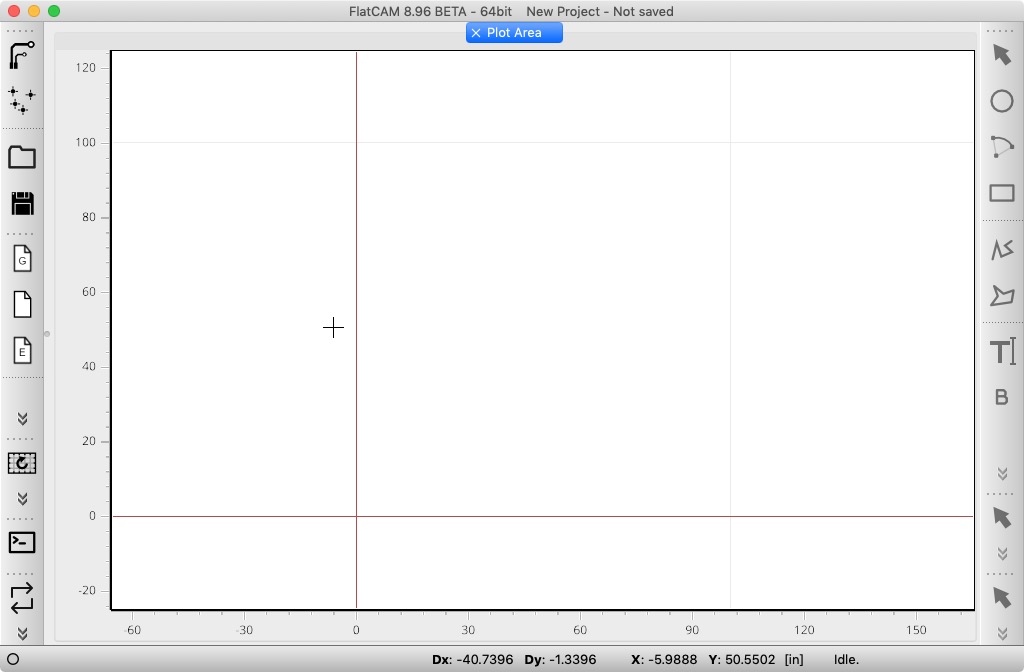
Once you're done, a window like the following will appear:
FlatCAM 8.86 Running in macOS Mojave
Caveats
I'm not sure why, but sometimes, when quitting the program, something fails and errors are returned. I'll have to live with it but if someone can help debug the issue that would be great
]]>Miguel Sánchez VillafánVirtualBox CentOS 7 Guest Auto Screen Resizing2019-03-17T01:04:56-06:002019-03-17T01:04:56-06:00https://mig8447.github.io/virtualbox/linux/2019/03/17/virtualbox-centos7-guest-auto-screen-resizingThis is a short post describing how to get the screen auto-resizing working in a CentOS 7 VirtualBox guest OS
TL;DR
Upgrade VirtualBox to at least 5.2.26
Re-install VirtualBox Guest Additions in the guest OS to match the new version
Reboot the guest OS
Enjoy
The situation
Across the years I've installed CentOS in its different versions into VirtualBox to test new software as it allows you to have a sandbox to play with and to return to a snapshot you took (Remember to take snapshots before playing around with your machine) in case your system ends up cluttered or even broken (Been there, done that).
All of the VMs that I've used with CentOS have worked just fine except for one thing, auto-screen resizing does not work. Recently I came across an update of VirtualBox whose additions seem to have fixed the issue, there were some blogposts I read about modifying the /etc/modprobe.d/vboxvideo.conf file and overwriting it with “options vboxvideo modeset=1", a thing which I didn't try because I didn't have the time to experiment back then, but today, just with a simple update of the Guest Additions it all started to work like a charm. Steps to install are written in the TL;DR section above.
It is worth noticing that my host OS is macOS 10.13.6 and that I updated the kernel of the machine a few days ago to kernel-3.10.0-957.5.1.el7.x86_64.rpm but it didn't help until I upgraded VirtualBox.
]]>Miguel Sánchez VillafánOracle APEX - The Power of Interactive Reports2019-02-24T16:17:21-06:002019-02-24T16:17:21-06:00https://mig8447.github.io/oracle/apex/2019/02/24/oracle-apex-the-power-of-interactive-reportsThis post intends to be an in-depth tutorial on Oracle APEX's Interactive Reports and their different options. This is the second in a series of posts about APEX
The views expressed here are my own and do not necessarily reflect the views of Oracle
This post was updated to work with Oracle Application Express 19.1 on October 2nd, 2019
APEX was designed with Database Applications in mind. Nowadays many people perform their day to day management with a spreadsheet software, it might seem simpler than getting a database set up for the task, but it really isn't. What if you had to share your excel file with your other store locations? Would you share it via e-mail? How would your changes be synced?
With APEX you have the power to change that with just a few clicks. Just upload your data as it is and it will generate an application with a report and a form for you. You'll be able to keep adding data while making your app available to other people so they can do the same.
The following steps will provide guidance on how to build an APEX Application from an orders spreadsheet and how to make APEX's Interactive Reports work for you.
Creating an Application from a Spreadsheet
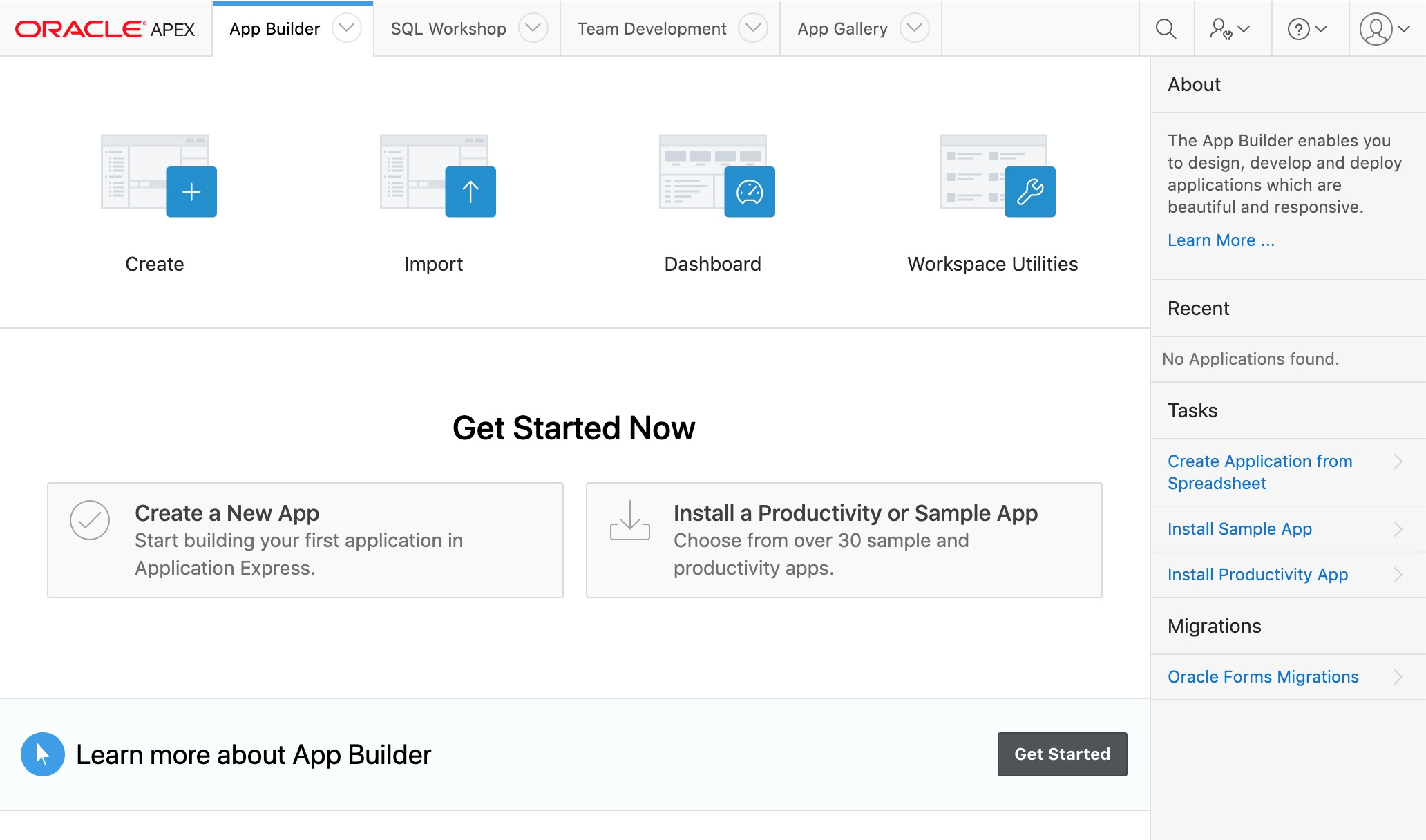
Once you have an APEX workspace set up and have accessed it. A screen like the one shown below should appear. Click on the Create button.
Application Builder Main Page
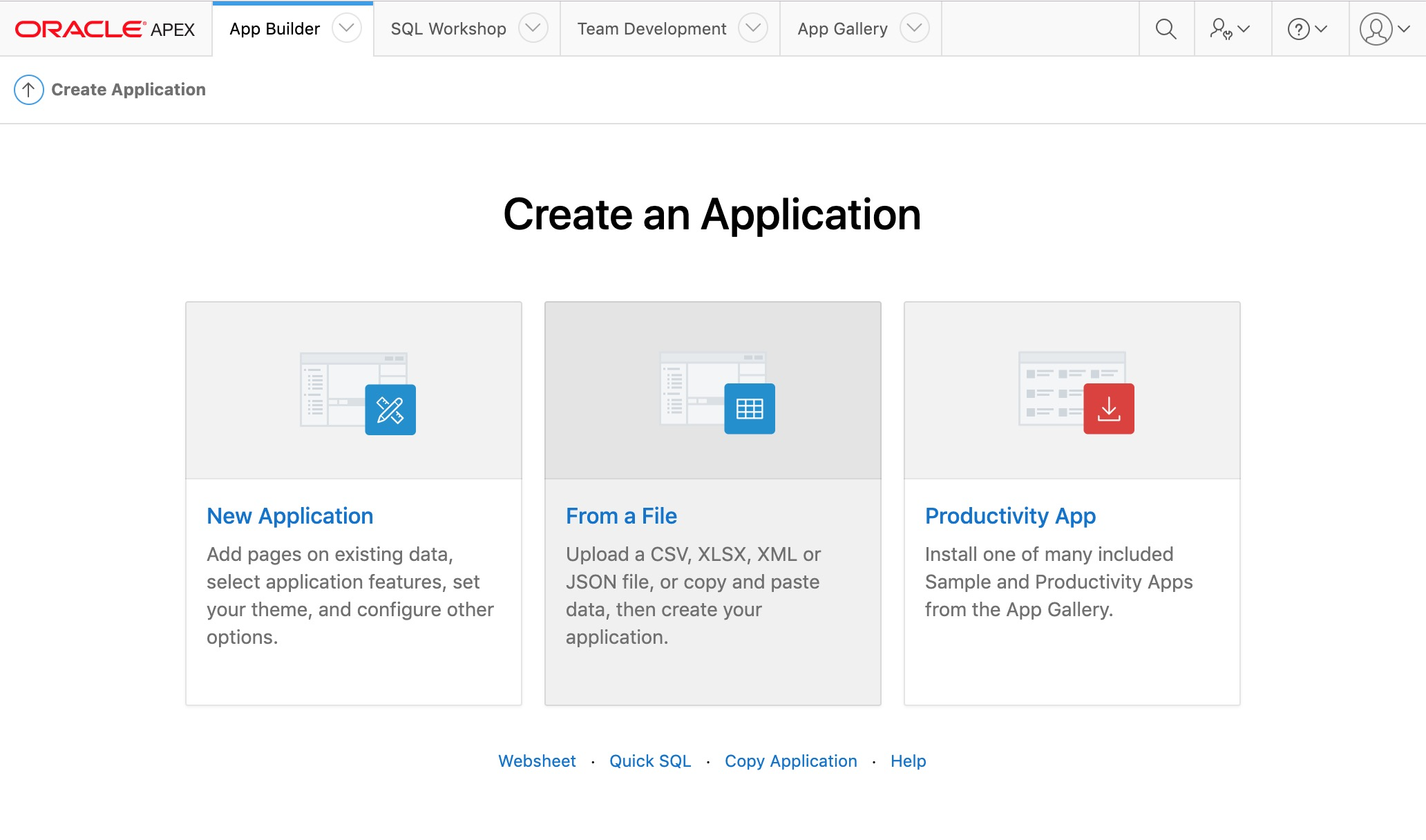
This will take you to the "Create an Application" page, where you can choose from a range of options to start creating your application. Click on "From a File".
Create an Application
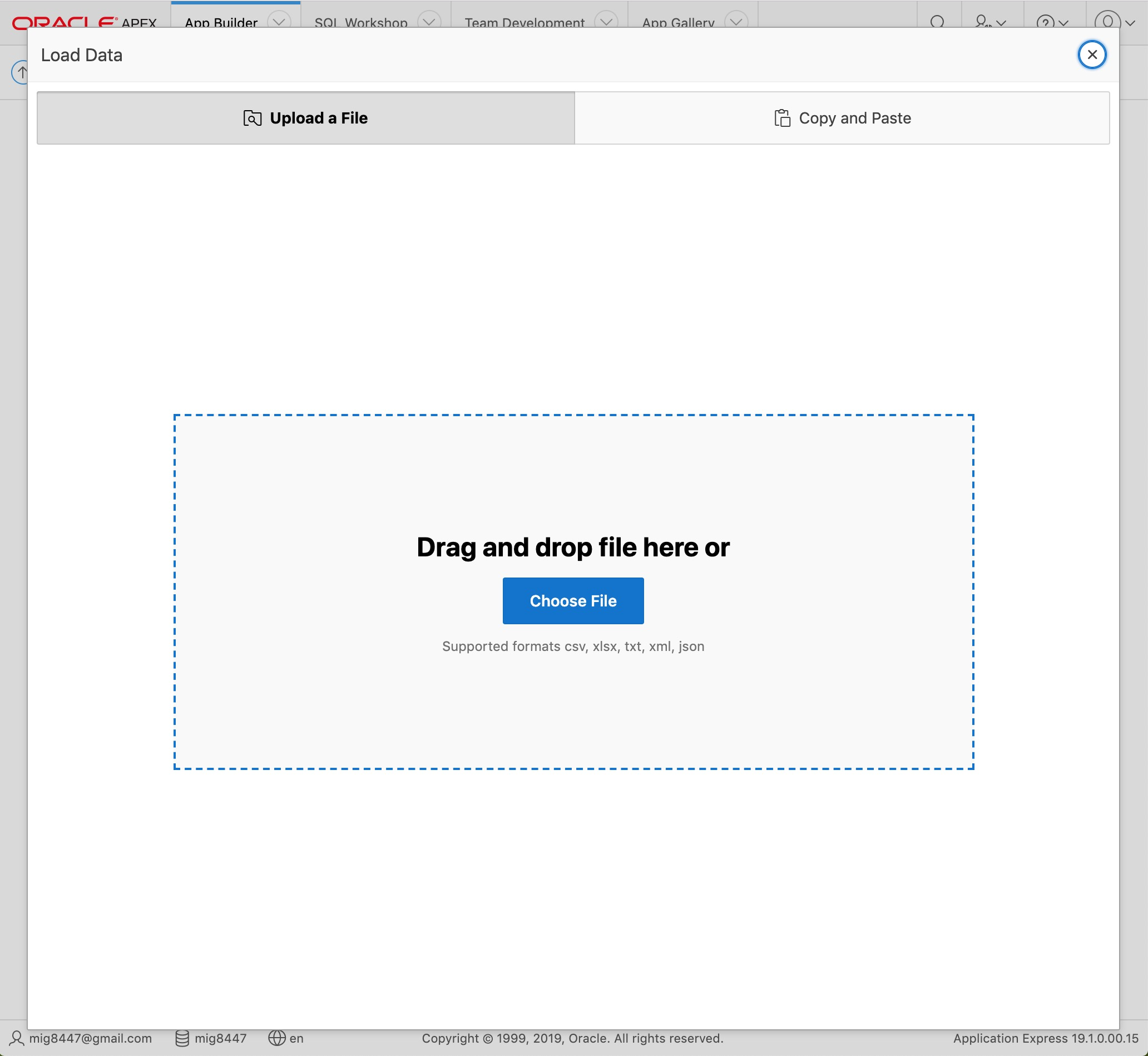
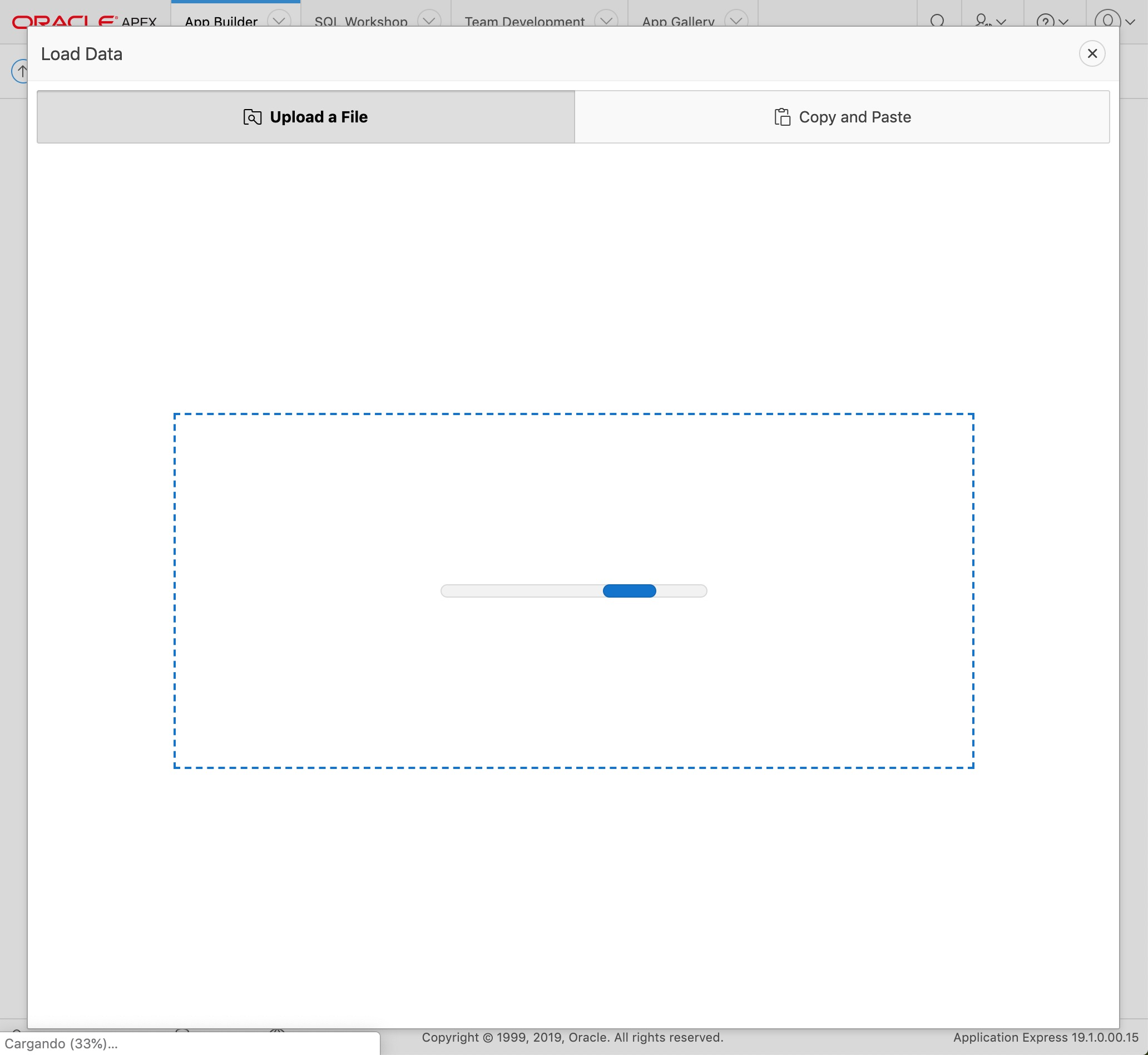
You will be presented with a dialog with two tabs. Make sure the "Upload a file" tab is active.
Load Data - Step 1
Uploading the Spreadsheet
Download the Orders.csv file. Drag and drop the recently downloaded file to the dialog and wait for the file to be uploaded.
Load Data - Step 2
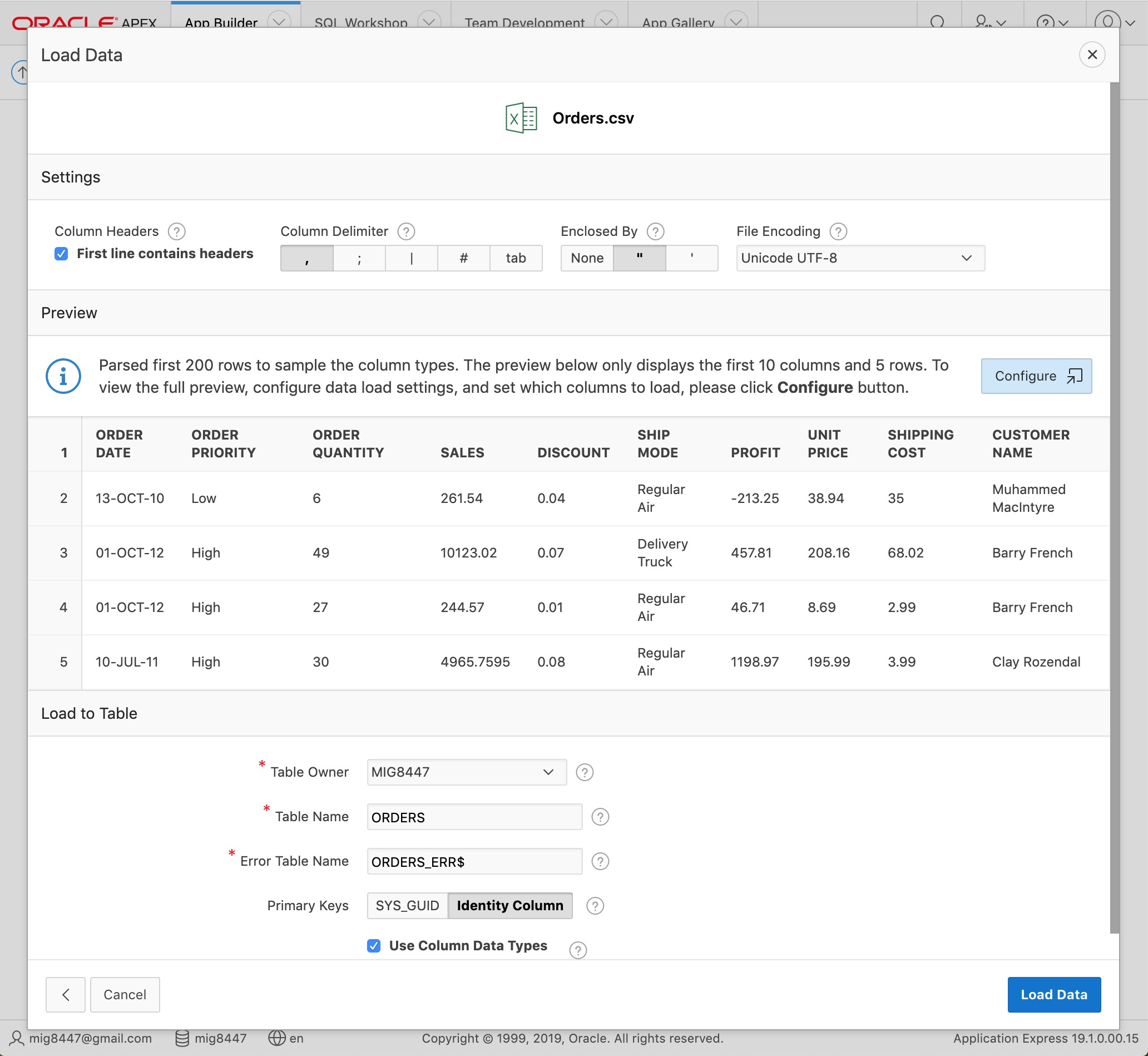
After a few seconds the below screen will appear. Write "ORDERS" in the "Table Name" field and continue by clicking the "Load Data" button at the bottom of the page.
Load Data - Step 3
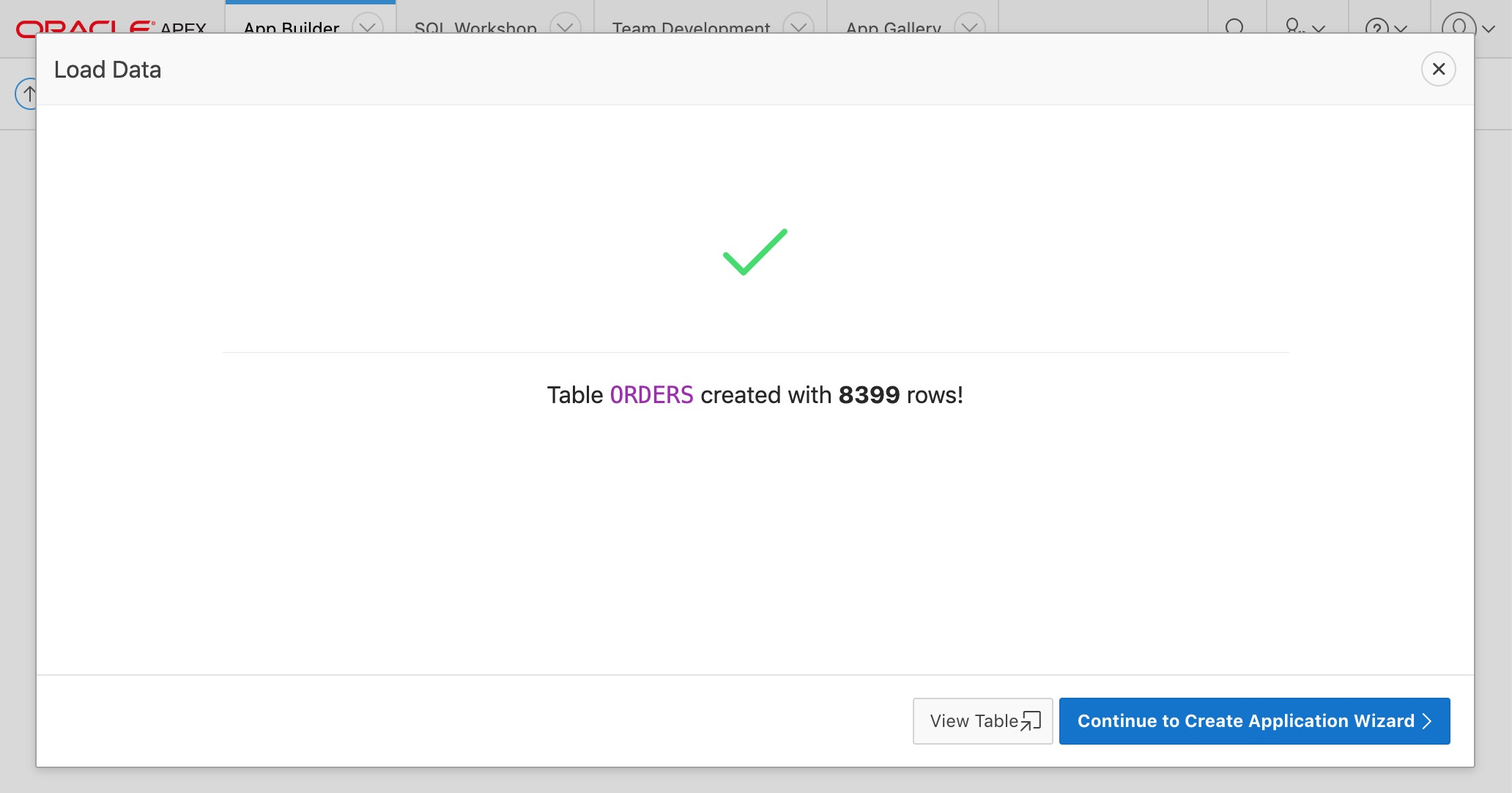
After the file is loaded the following screen will be shown.
Load Data - Step 4
Click on the "Continue to Create Application Wizard" button.
Configuring the Application
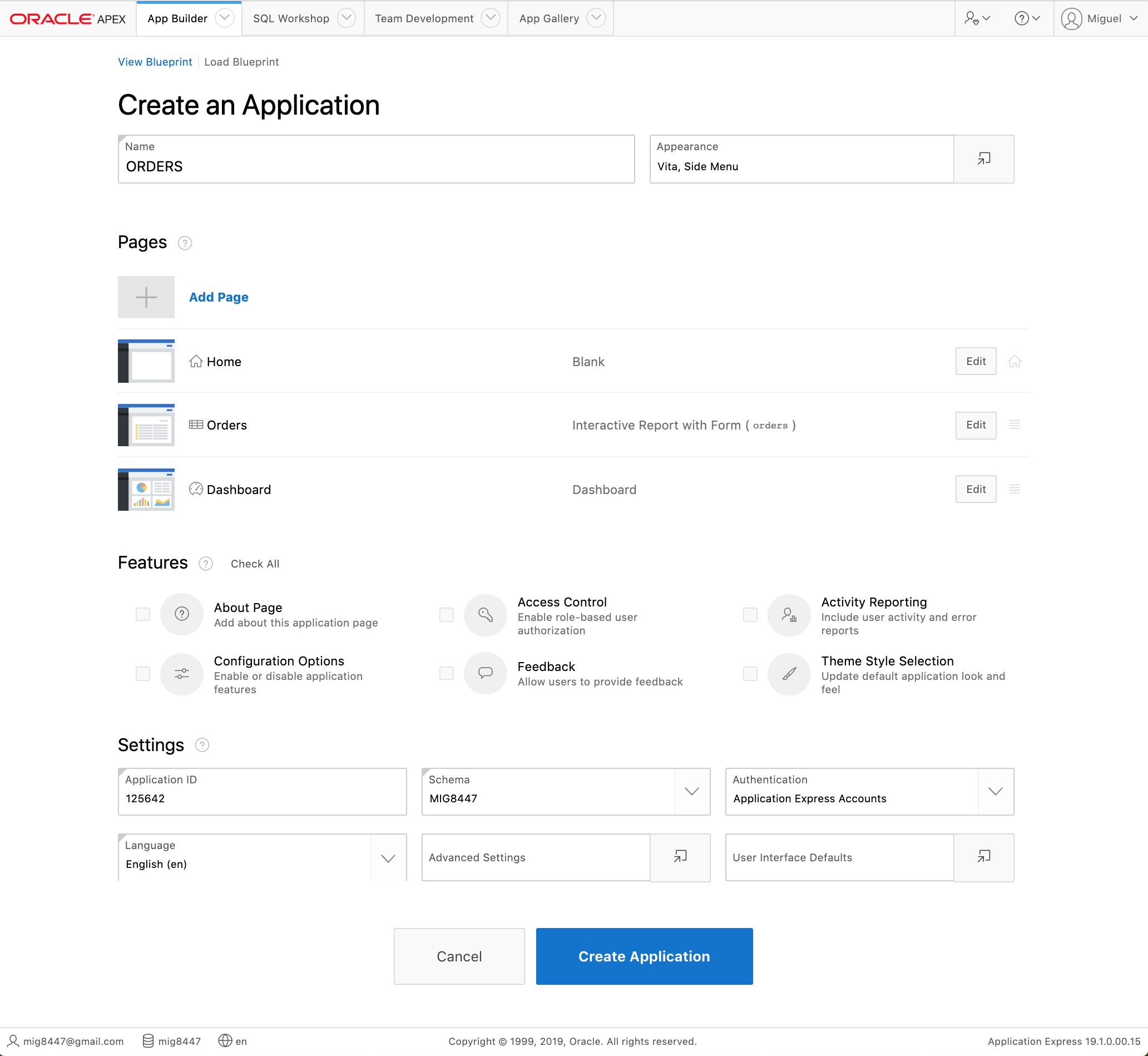
Enter "ORDERS" into the "Name" field and click the "Create Application" button at the bottom of the page.
Create an Application
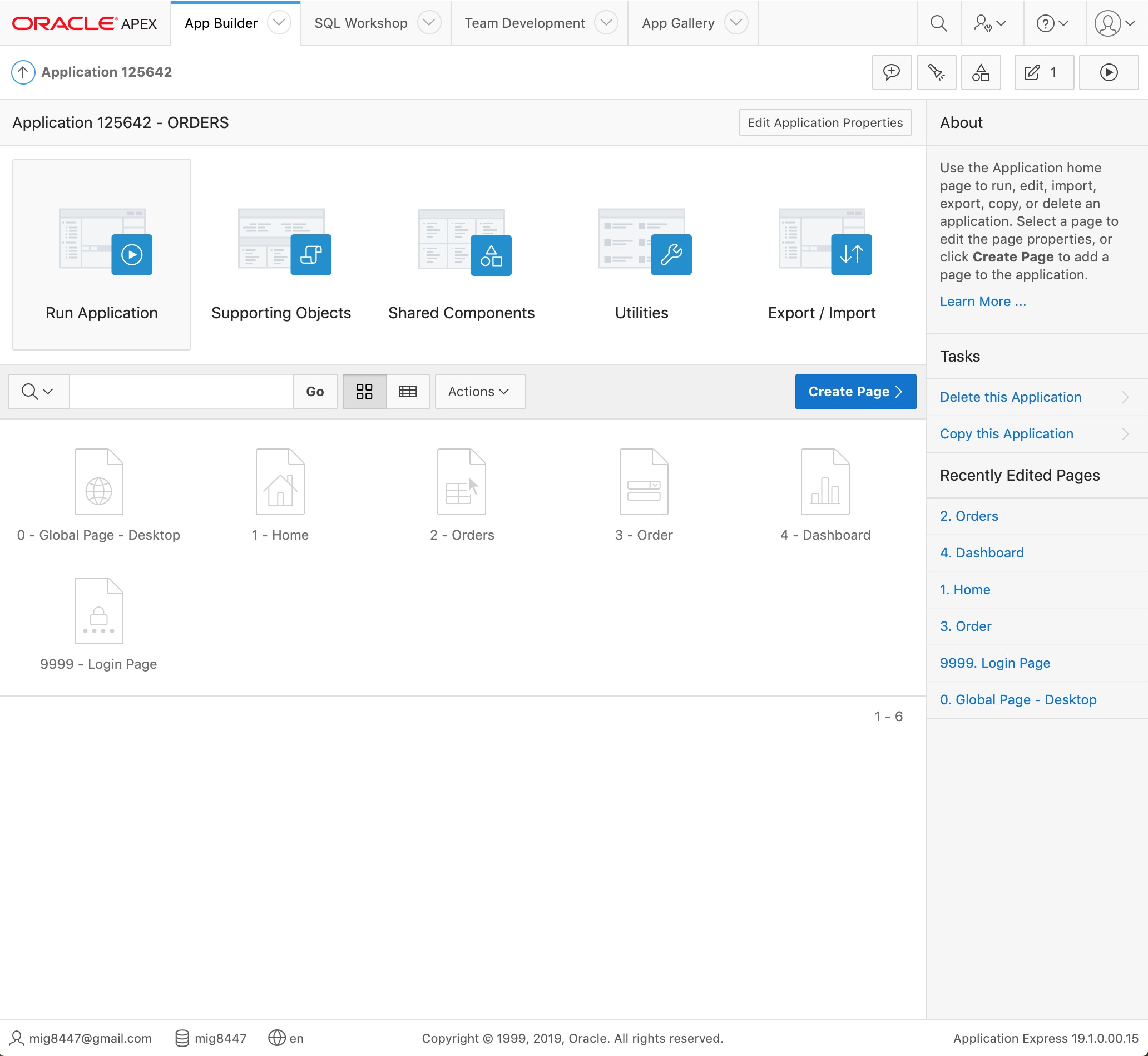
The "Application Builder" is displayed with our application, for which six pages have been created.
Application Builder - ORDERS Application
Running the Application
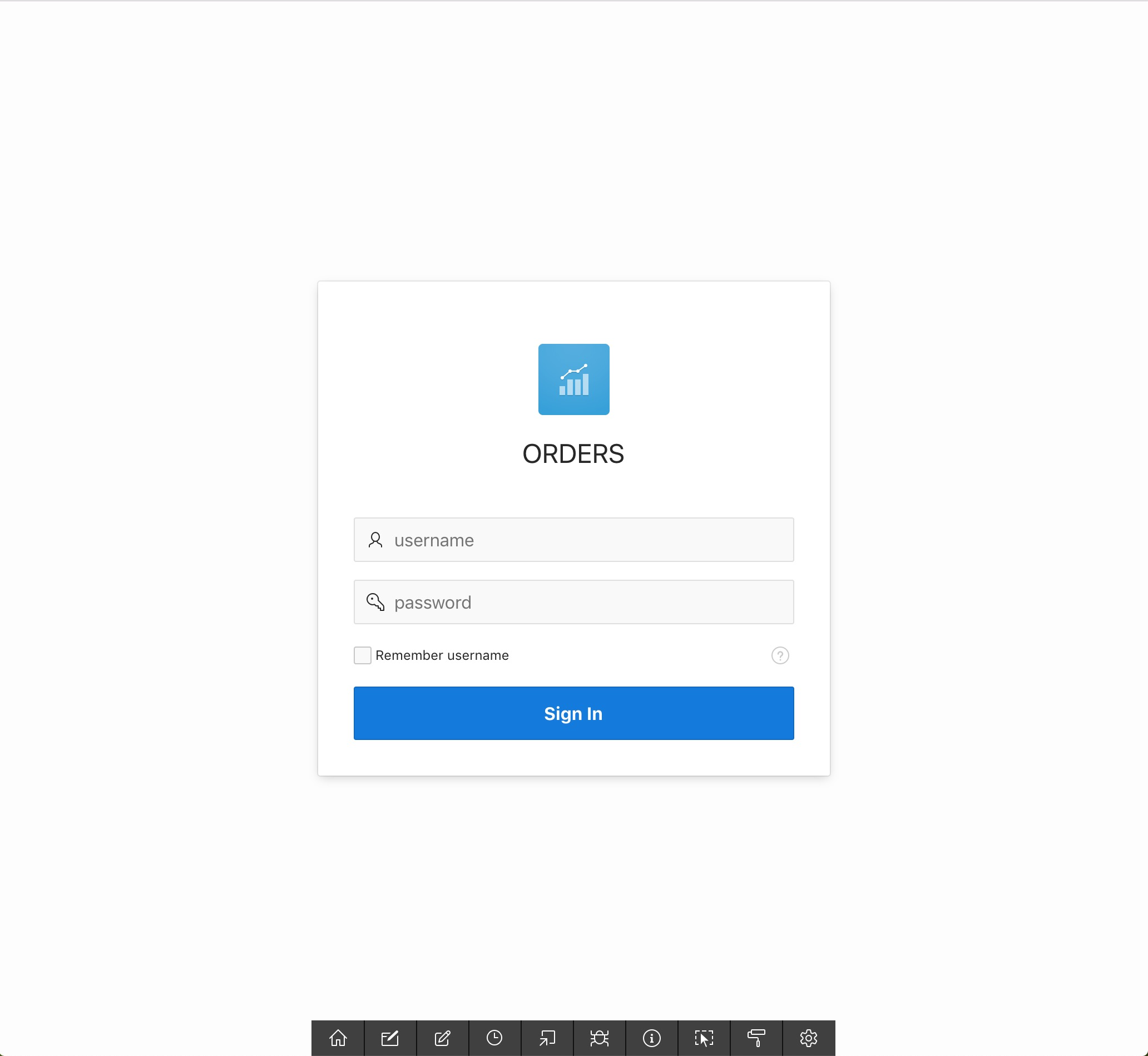
Click on the "Run Application" icon at the top of the page. The application user login will appear.
ORDERS Application - Login Page
Enter your workspace login details and click on the "Sign In" button.
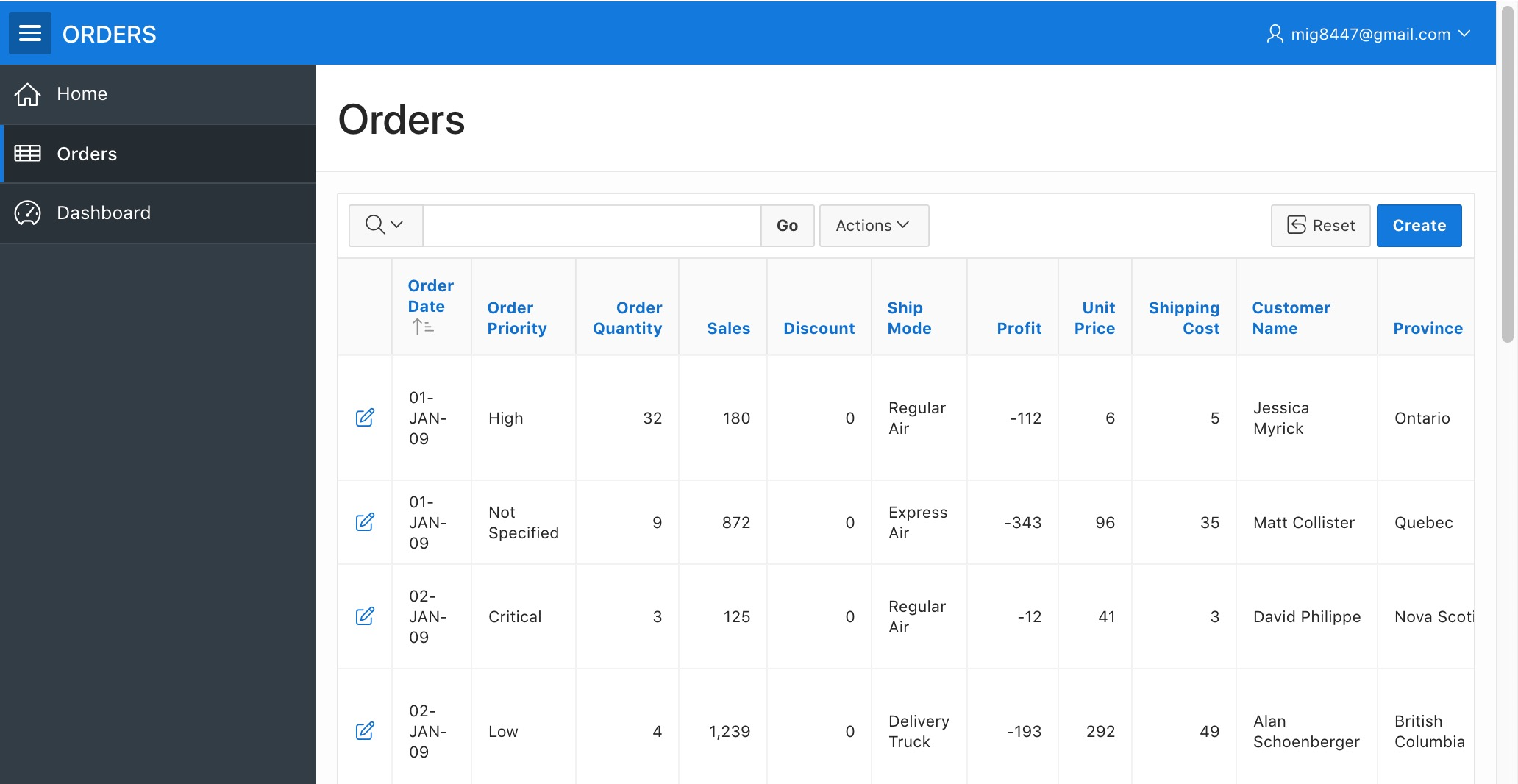
You will now see the Home Page, click on the "Orders" button from the page or from the navigation menu. Then a report with all the uploaded data will be shown.
ORDERS Application - Orders Page
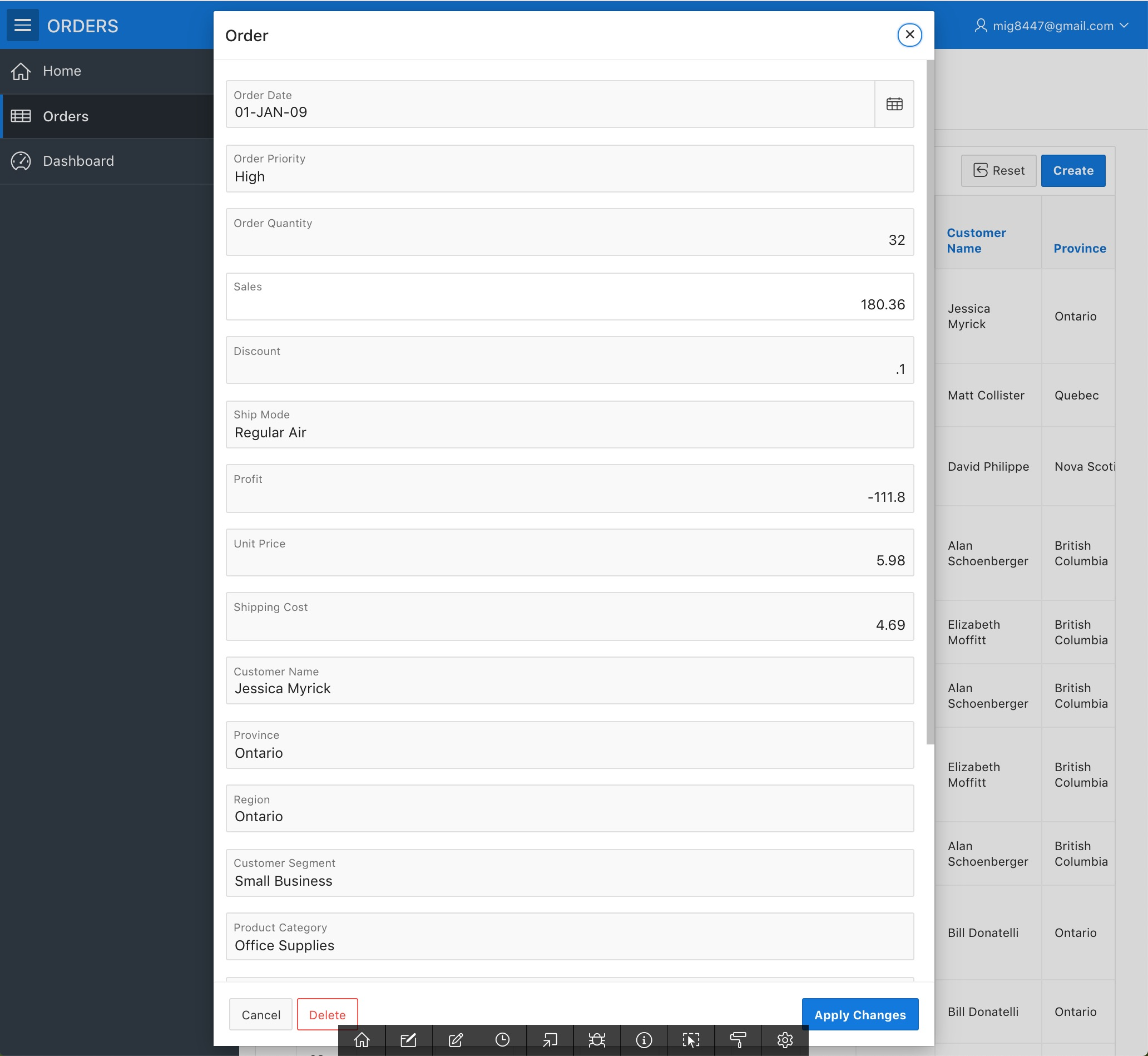
Doesn't seem like much, but wait to see the following. Now click on one of the pencil icons at the beginning of the rows.
A form will appear, this was created automatically based upon the uploaded data.
ORDERS Application - Orders Form
It will allow you to get new data into the database you now have. Scroll down and click on the "Cancel" button. We will now remove the clutter from our report.
Unleashing the Power of the APEX Interactive Reports
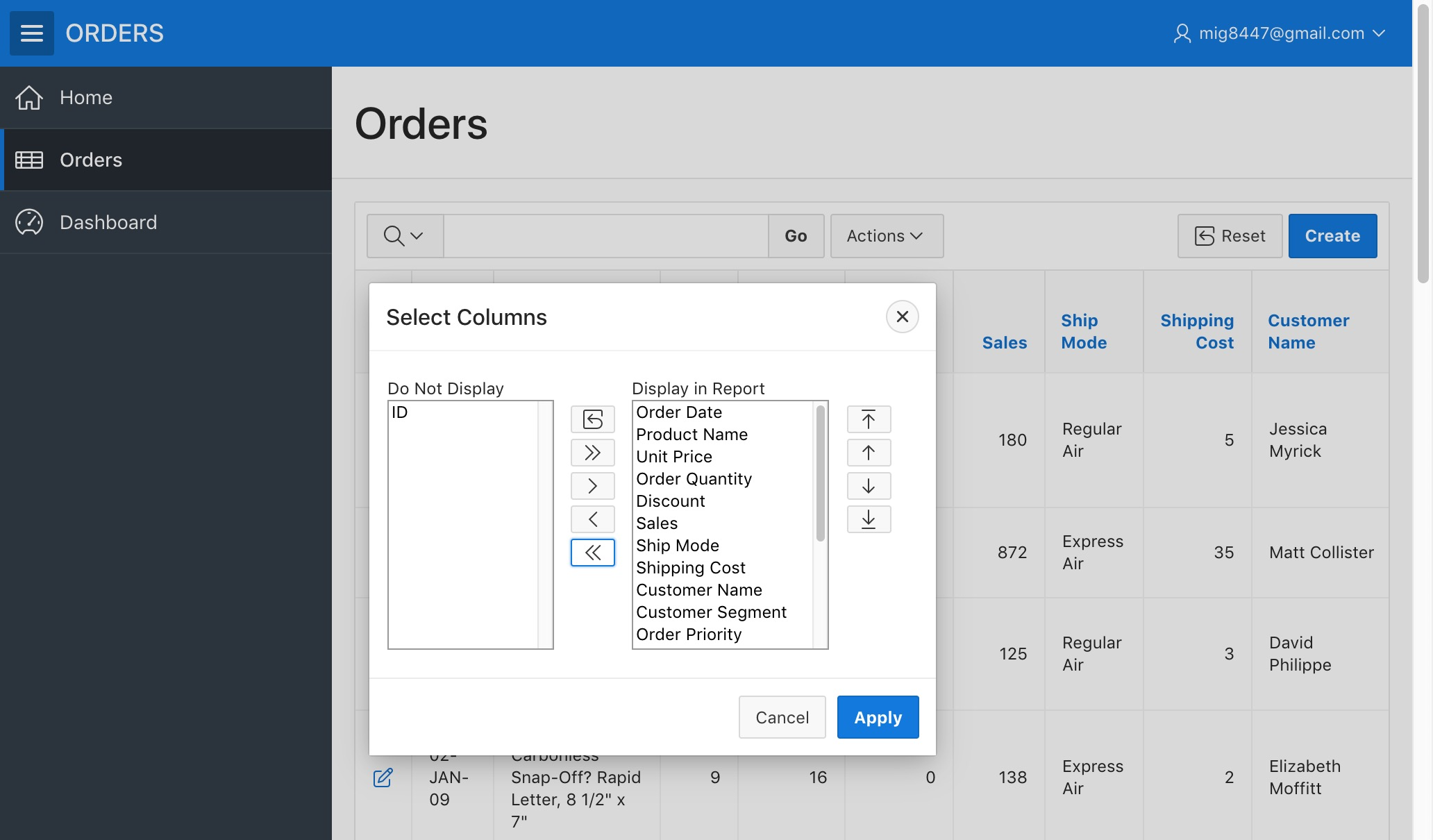
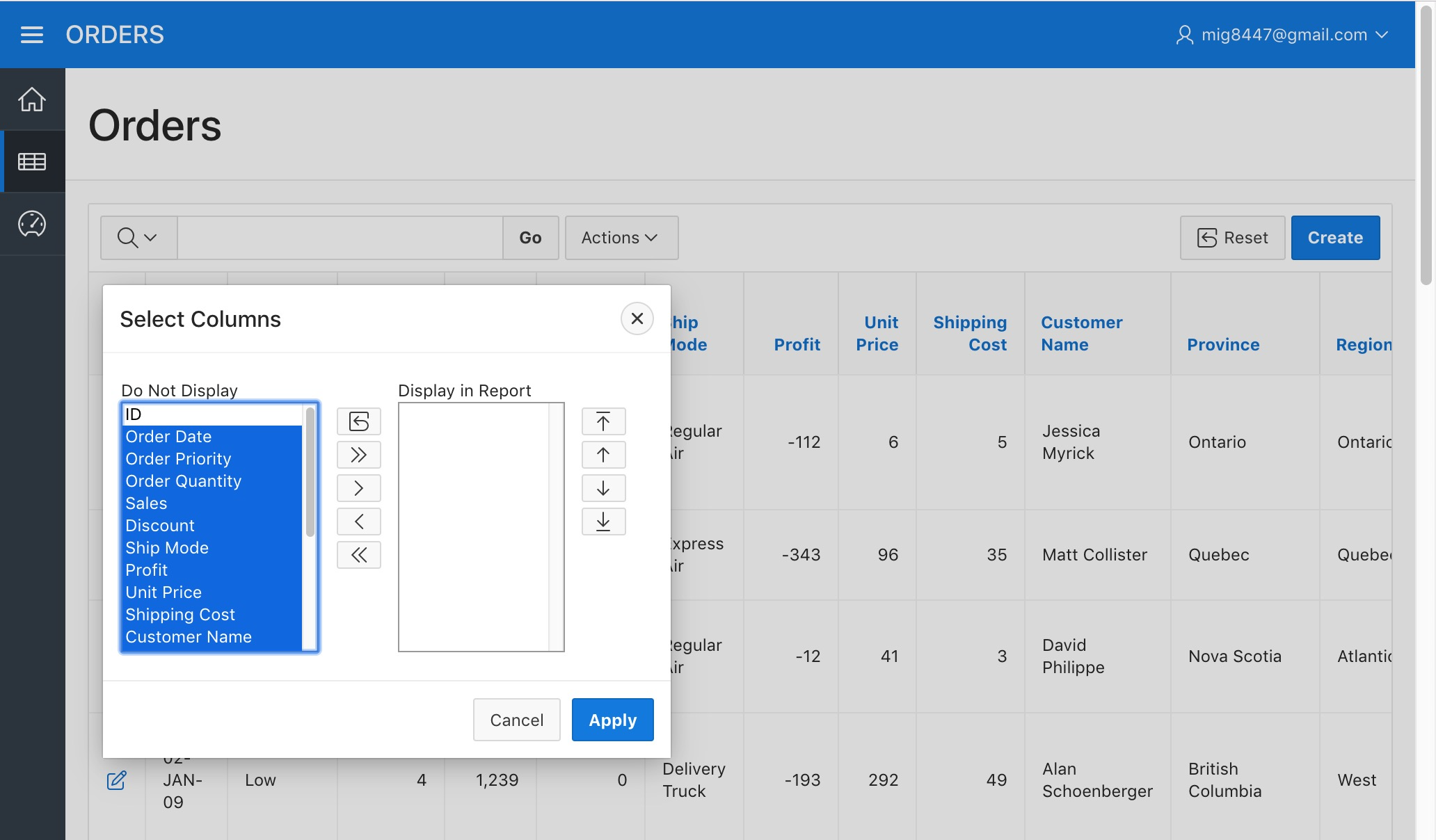
Sometimes there's data in the report we don't always need to see. With the help of APEX's interactive reports we can select the data columns we want to see. Click in the "Actions" menu next to the search bar and then pick the "Columns" option from the menu.
Orders Report - Columns Menu
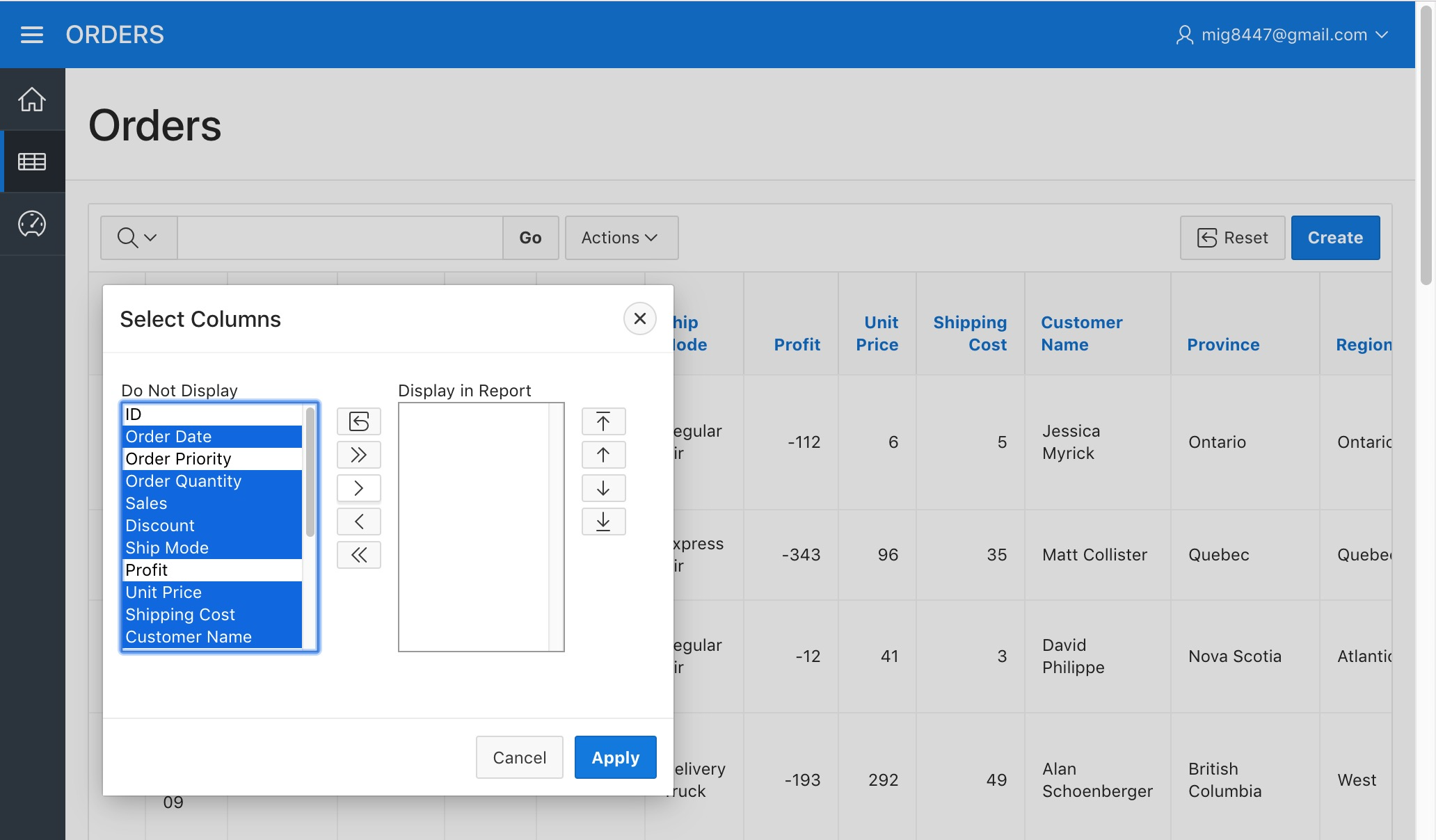
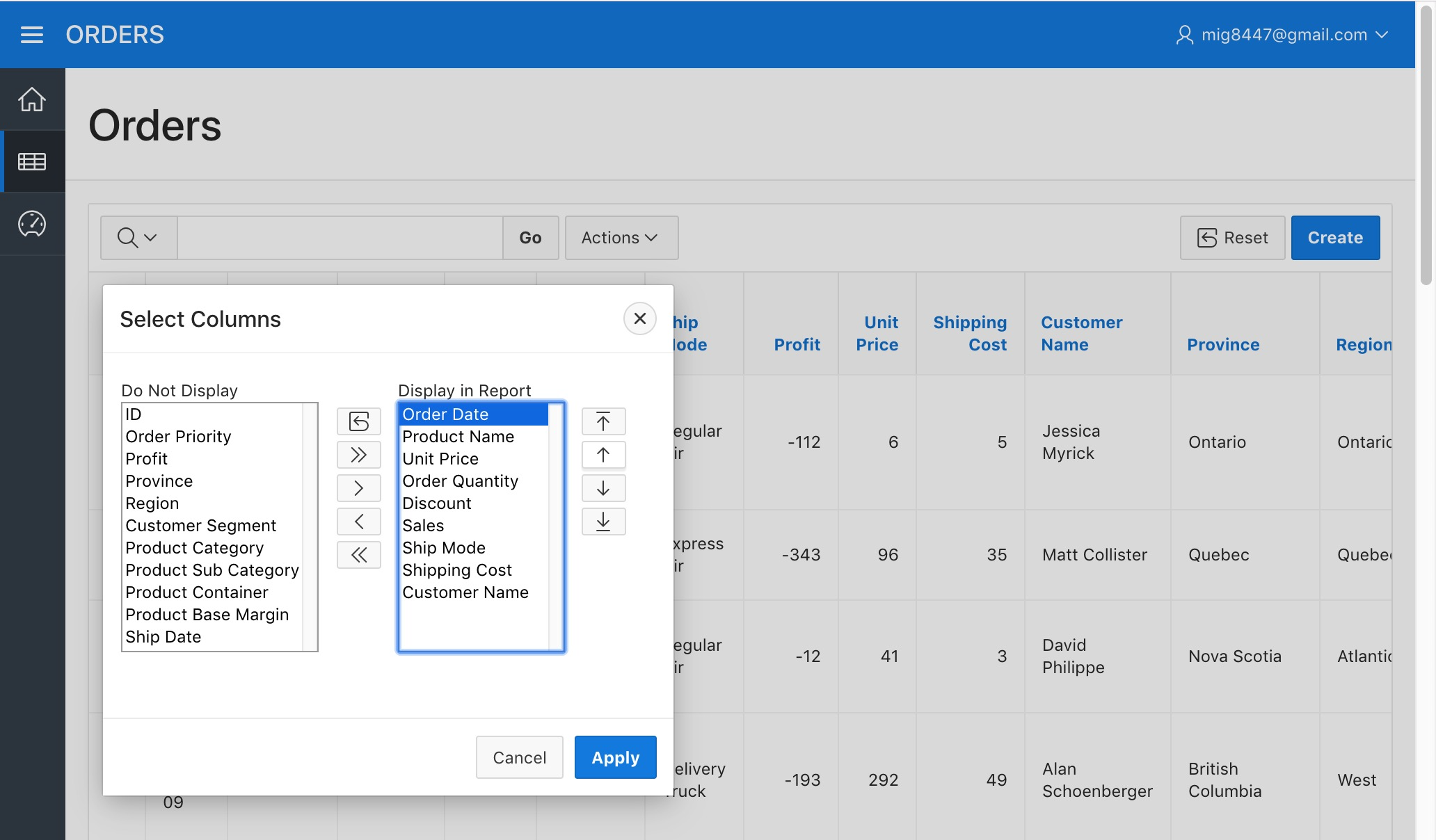
A dialog will appear. Click on the "«" button displayed on the dialog, this will hide all the columns in the report.
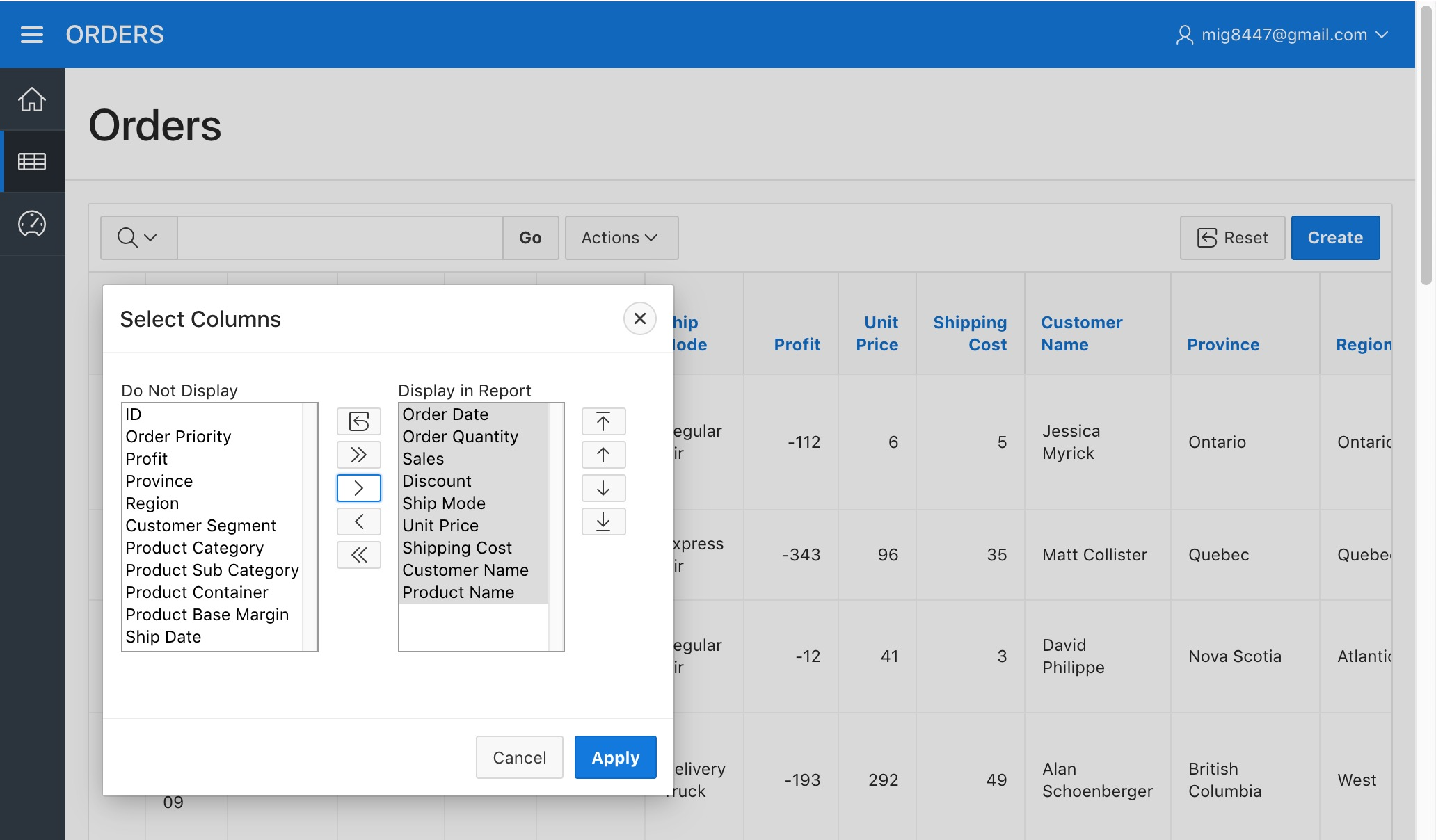
We'll now pick the columns we want by selecting their names (You can select multiple items with Shift + Click) in the "Do Not Display" column and clicking on the ">" button. Pick at least Order Date, Product Name, and Sales to be displayed.
You can reorder the names by clicking the icons located to the right of the "Display in Report" column
Orders Report - Column Sorting
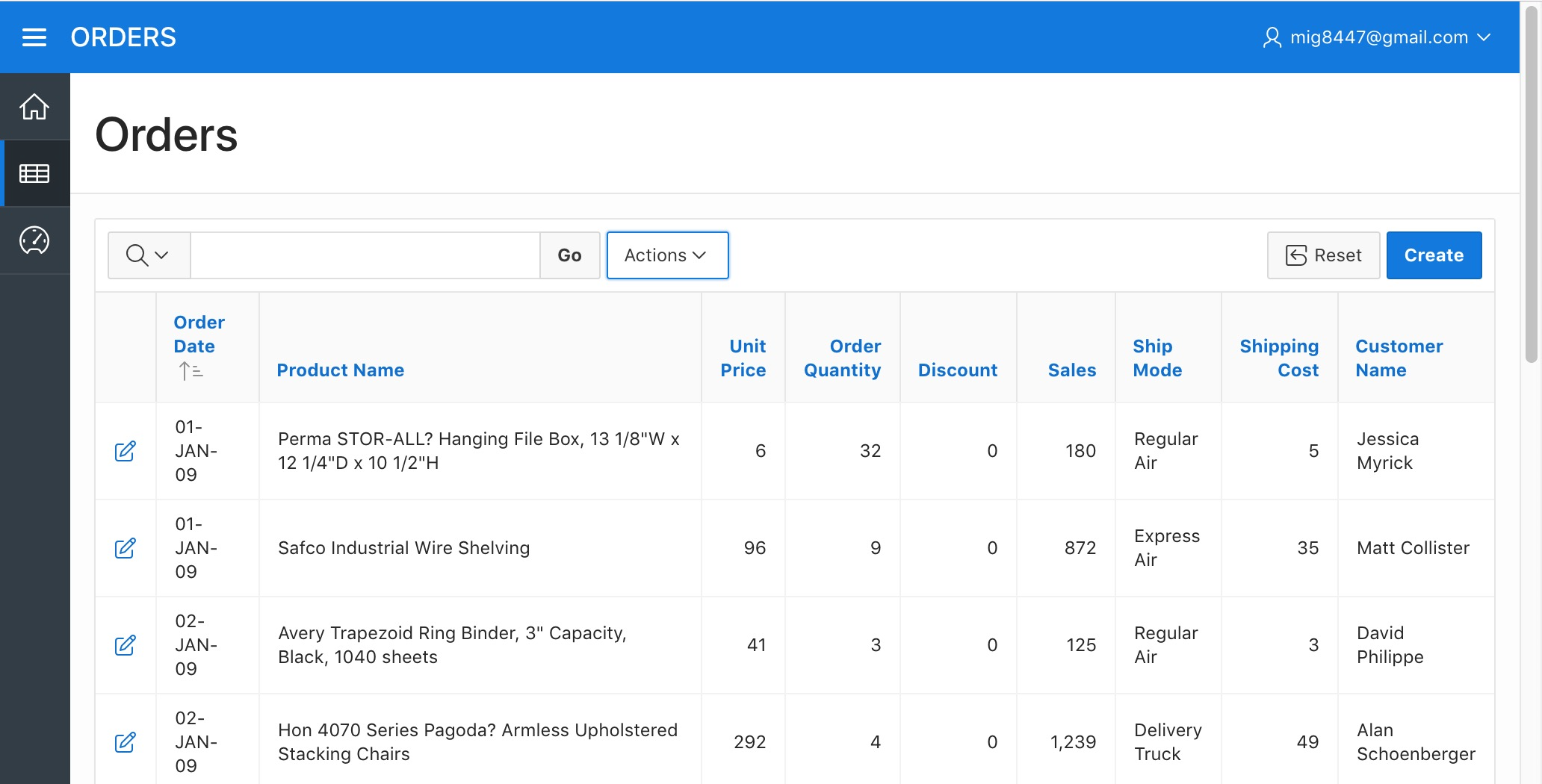
Click on the "Apply" button. A more simplified report will appear.
Orders Report - Simplified Report
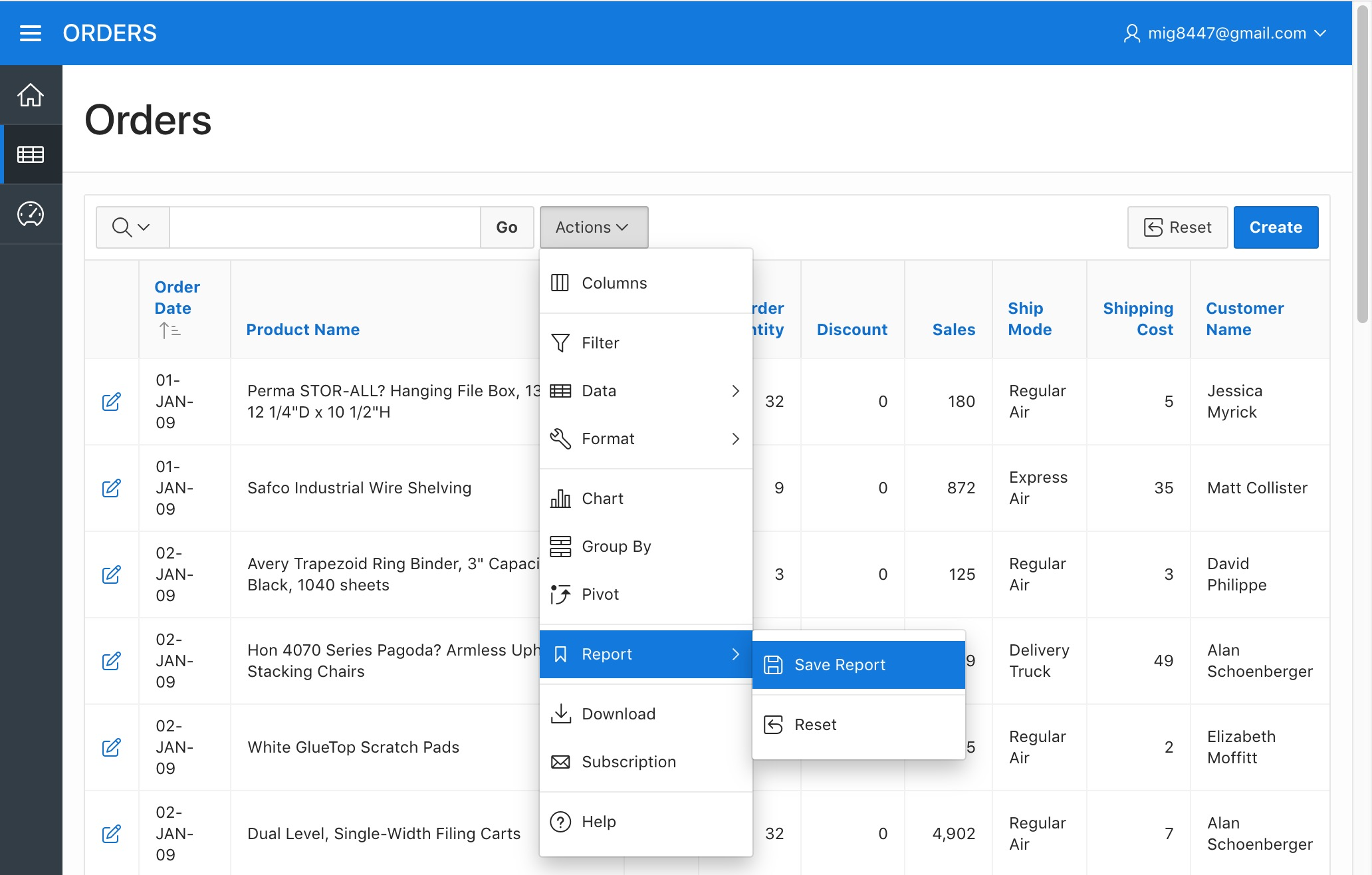
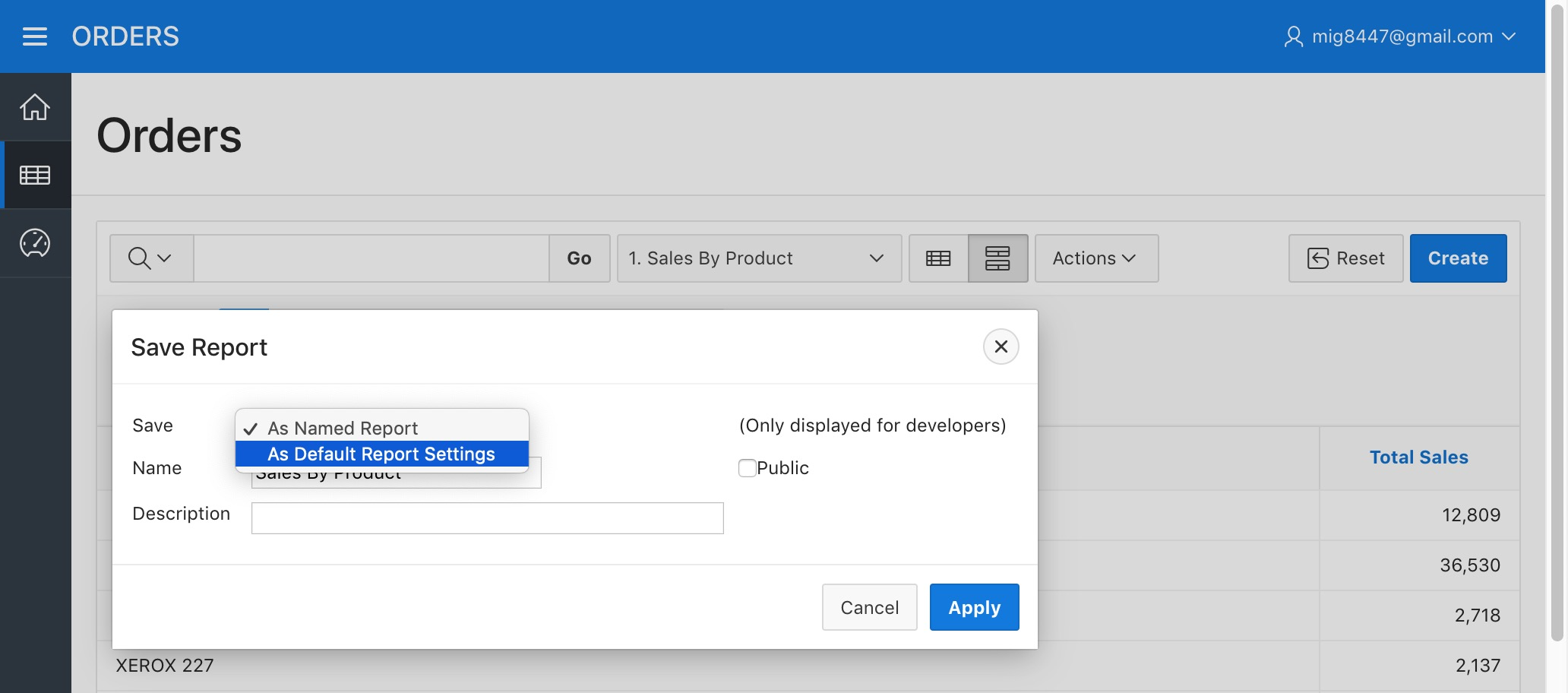
Lets use the "Actions" menu once more by picking the "Save Report" option from the sub-menu "Report".
Orders Report - Save Report Menu
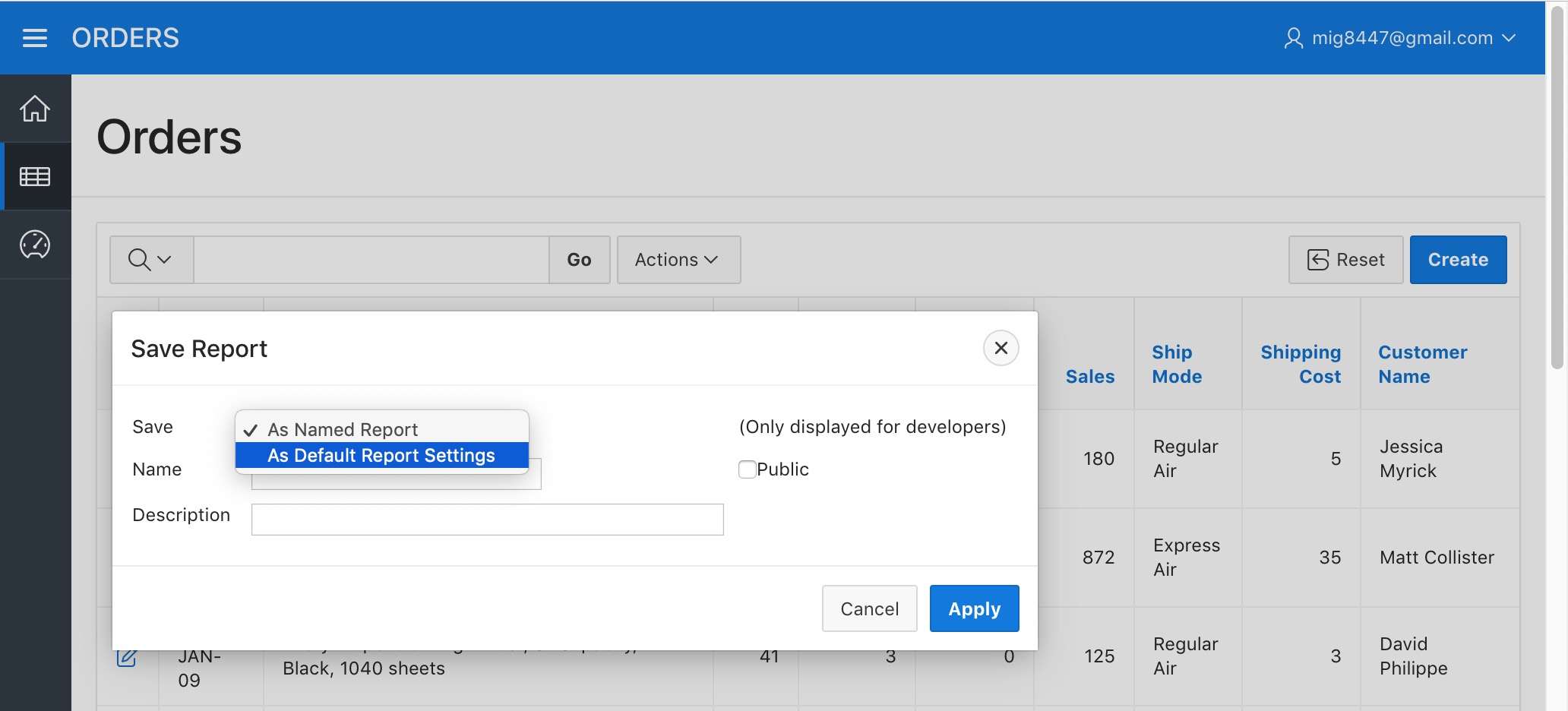
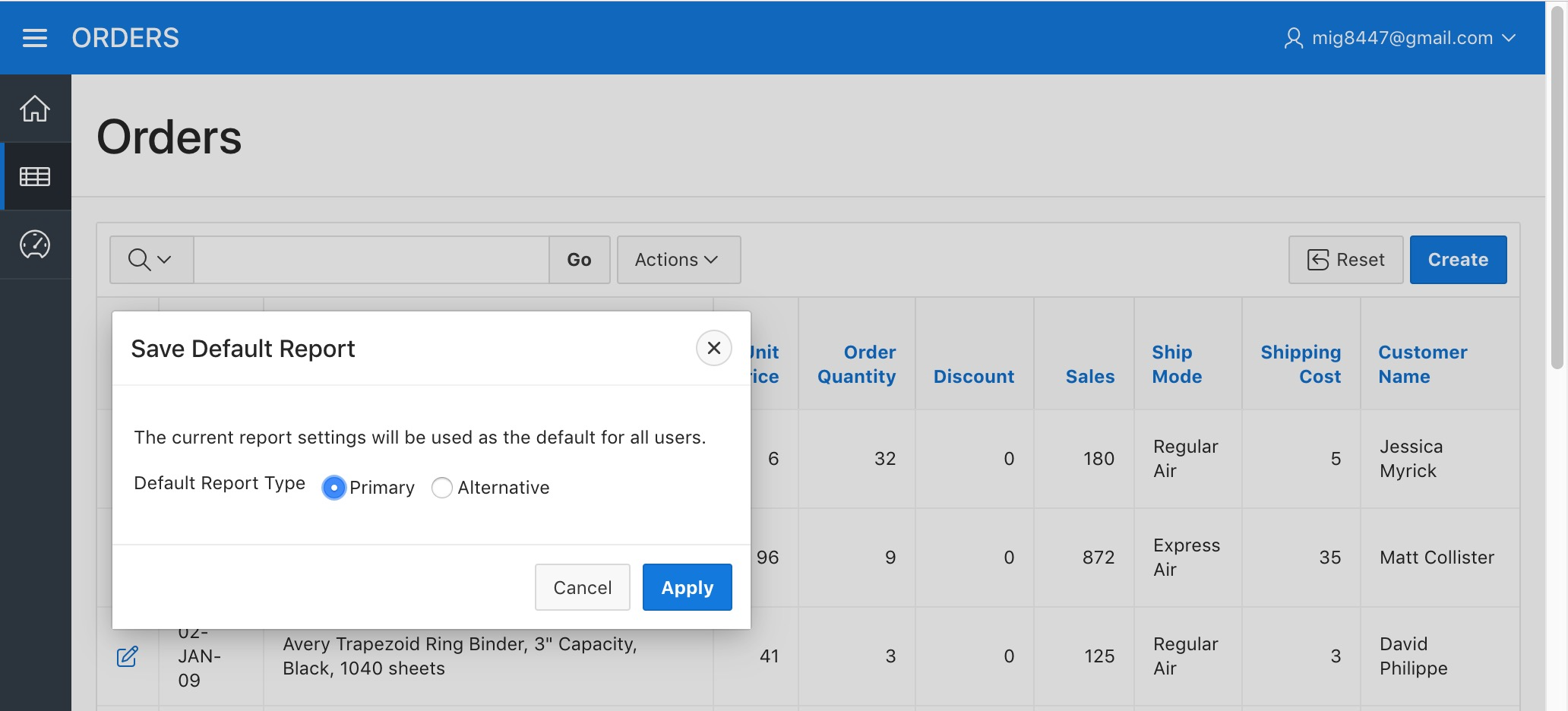
A dialog will appear. Pick the "As Default Report Settings" option on the "Save" field.
Orders Report - Save Primary Report Step 1
The dialog will change. Select the "Primary" option and click "Apply".
Orders Report - Save Primary Report Step 2
By doing this we're telling APEX to make this simplified view of our table the default view for all the Application users. Now, when someone enters the Orders page they will see the report as it is now. Lets make it more interesting.
Data Computations - Normalizing the Product Names
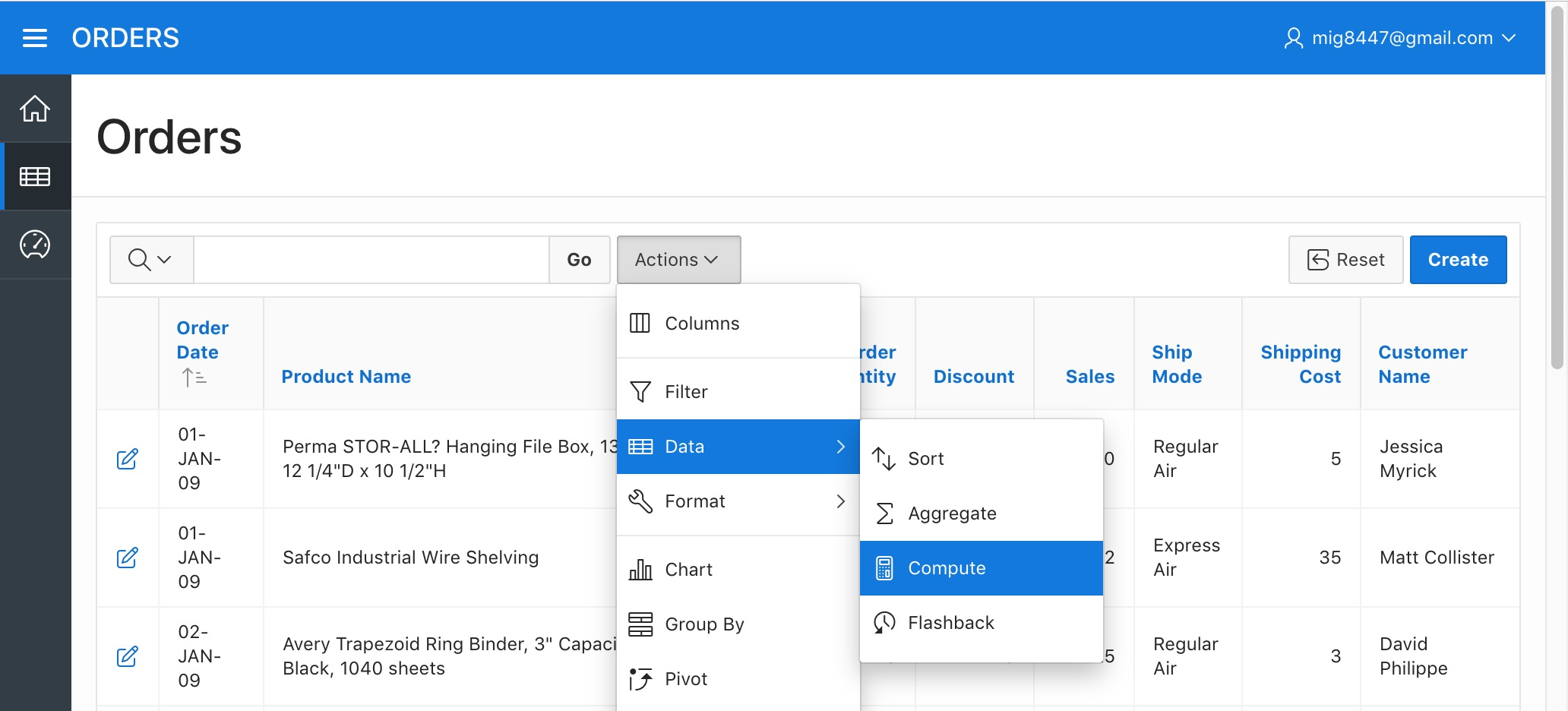
Click on the "Actions" menu once more and hover over the "Data" option, then pick the "Compute" option in the sub-menu. We will now generate a couple of columns that are said to be "computed", meaning that such columns will have calculated values, normally depending on the original report columns.
Orders Report - The Compute Menu
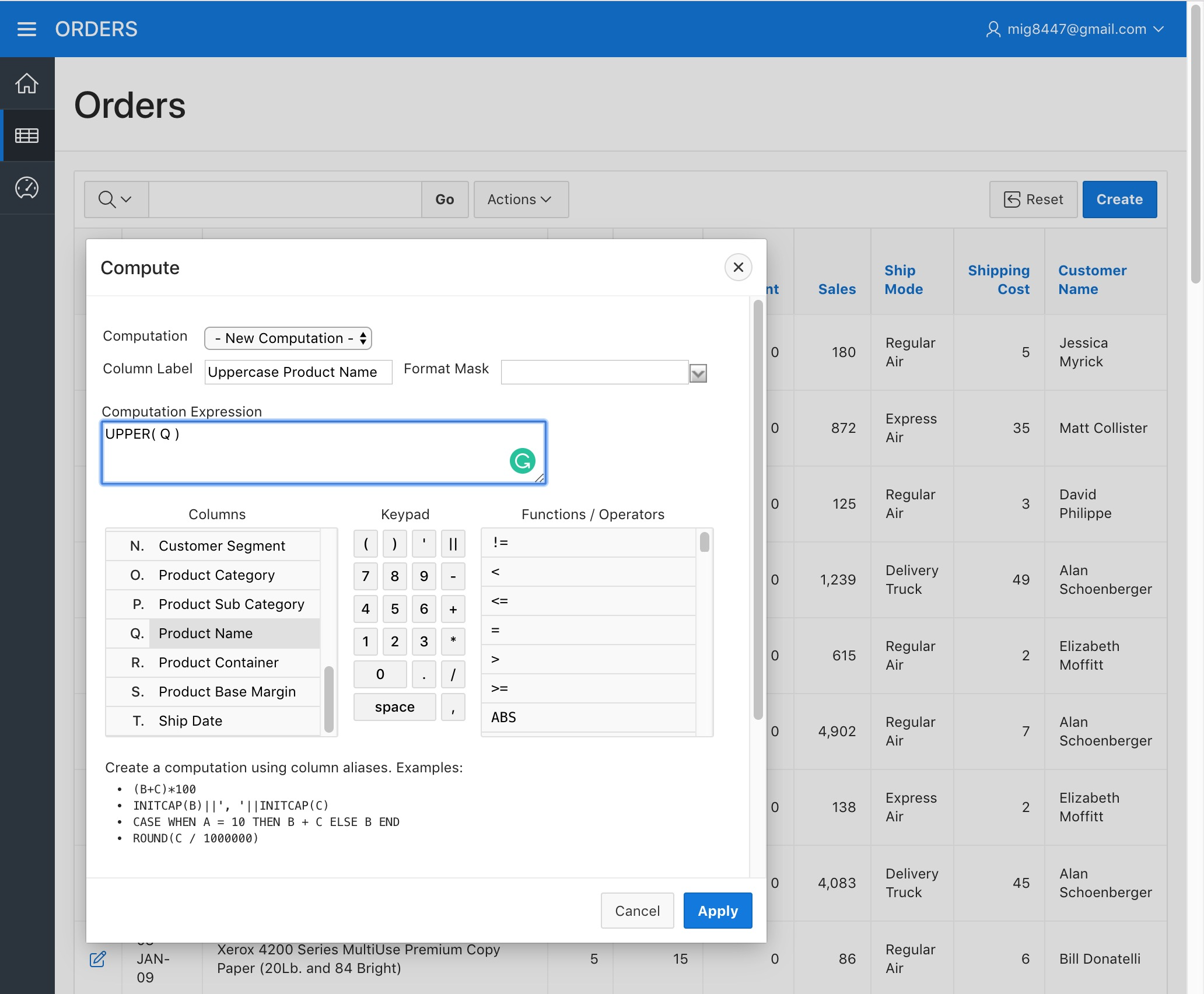
A dialog will appear. Enter "Uppercase Product Name" as the "Column Heading" and now type the following as the "Computation Expression":
UPPER( Q )
Make sure the Q letter corresponds to the "Product Name" column under the "Columns" list, if it doesn't, then replace it with the letter that corresponds to it. You can find all the supported operations for these "Computations" under the "Functions / Operations" list. Click "Apply"
Orders Report - Compute Uppercase Product Name
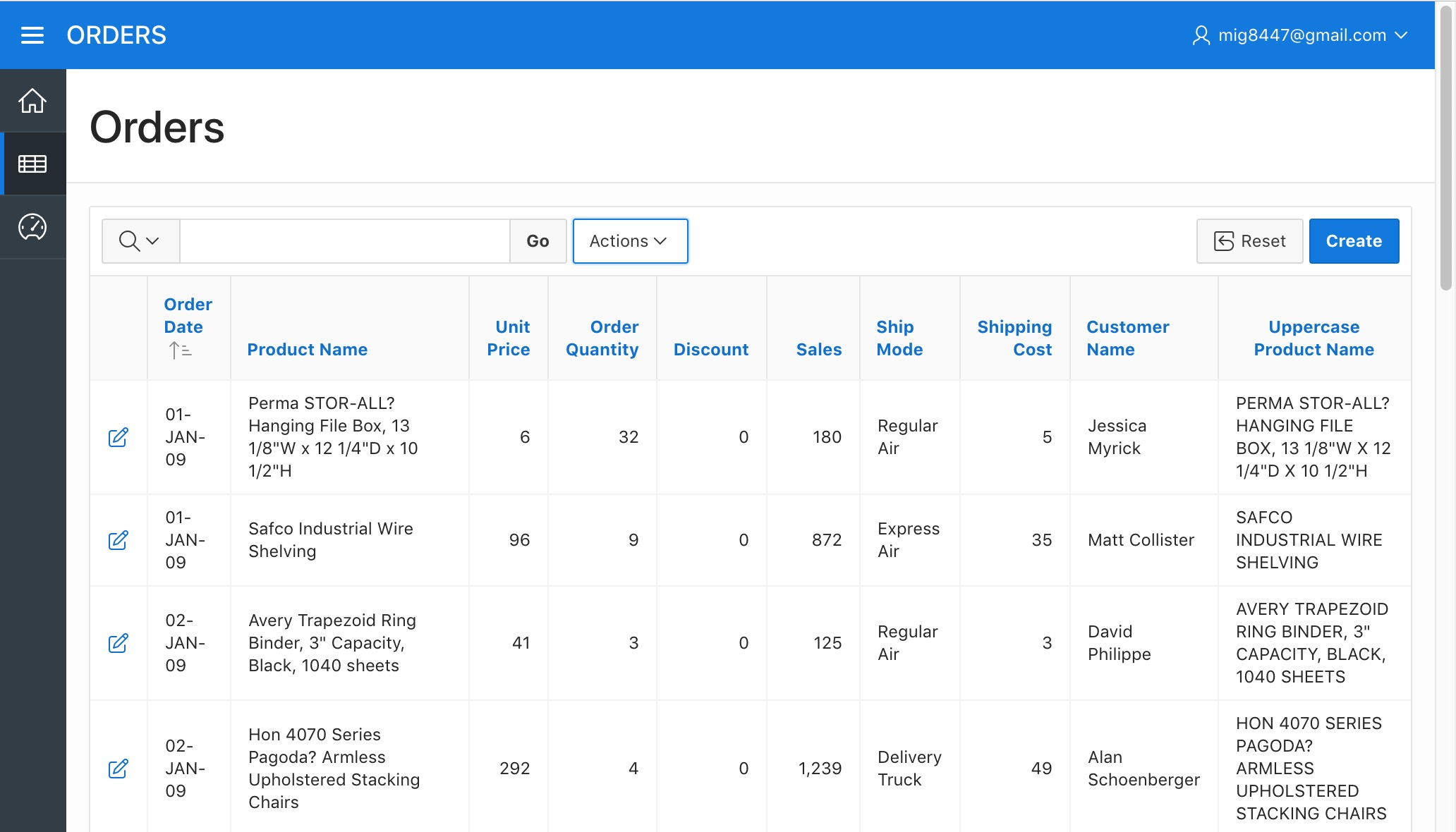
We now see the "Uppercase Product Name" at the right side of our report.
Orders Report - Created Uppercase Product Name Column
This column will be useful because the Orders.csv file contained product names that were just different in the character case used, some product names, although the same were captured all uppercase, some with lower case and some with mixed case. With the "Uppercase Product Name" column we have something that we know will be consistent independent of the character case it is written on.
Can we have a "Sales by Product" report? Yes. Interactive Reports allow us to group things by one or more columns.
Grouping Data - Creating a "Sales by Product" Report
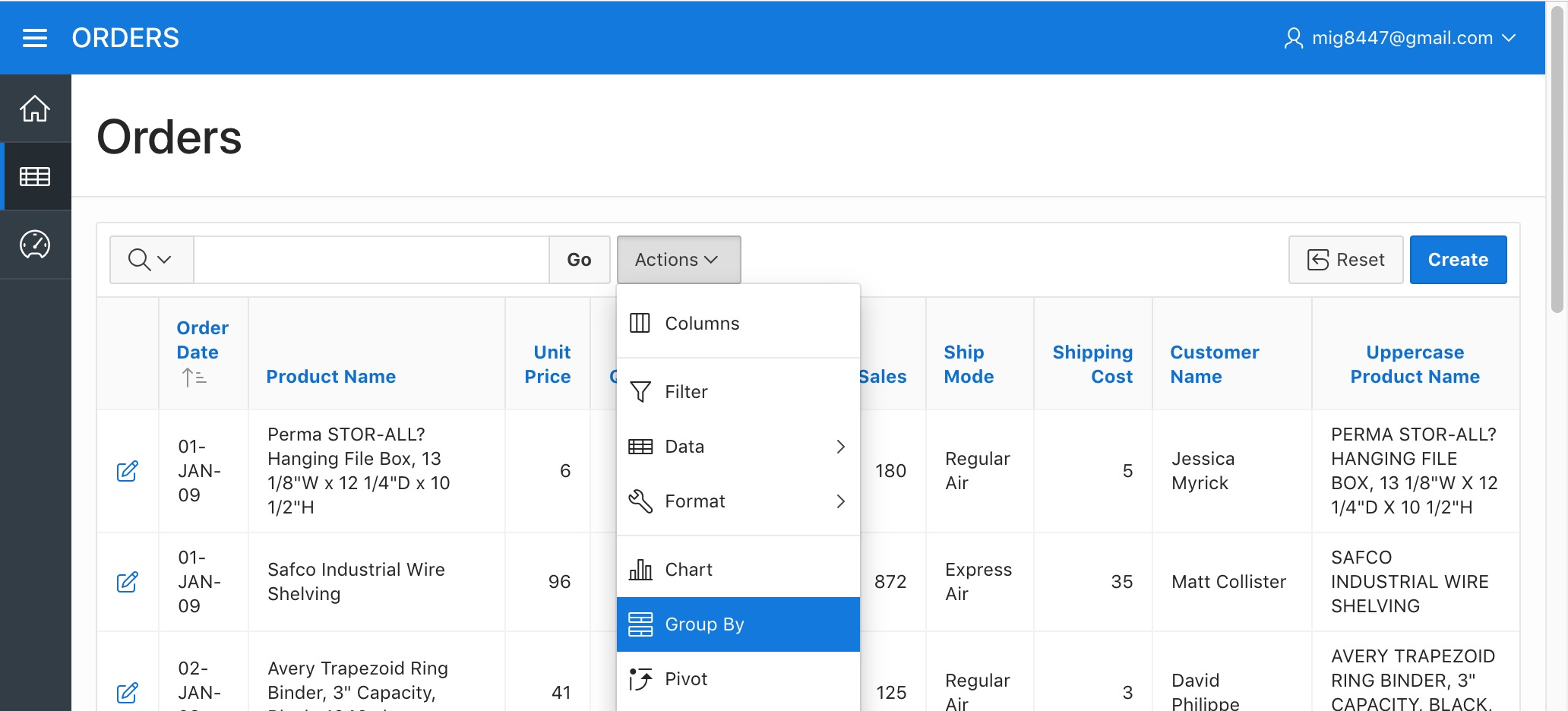
Click on the "Actions" menu and select the "Group By" option.
Orders Report - Group By Menu
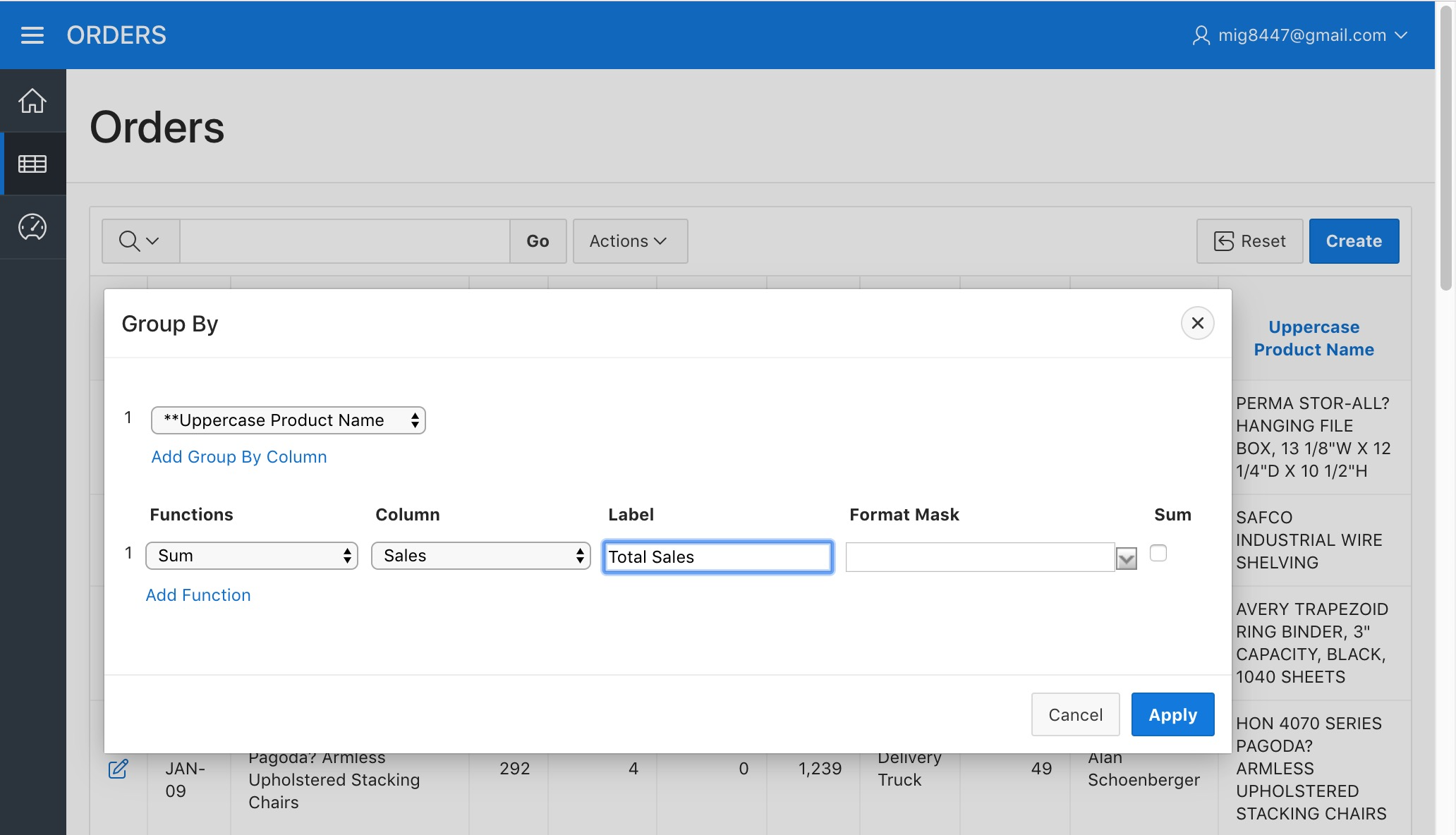
A dialog will open. Select the "**Uppercase Product Name" column (The two asterisk characters before the name mean that the selected column is a "Computed" column) as the "Group By Column", "Sum" as the "Function", "Sales" as the "Column" and type "Total Sales" as the "Label". Then click "Apply".
Orders Report - Group By Uppercase Product Name
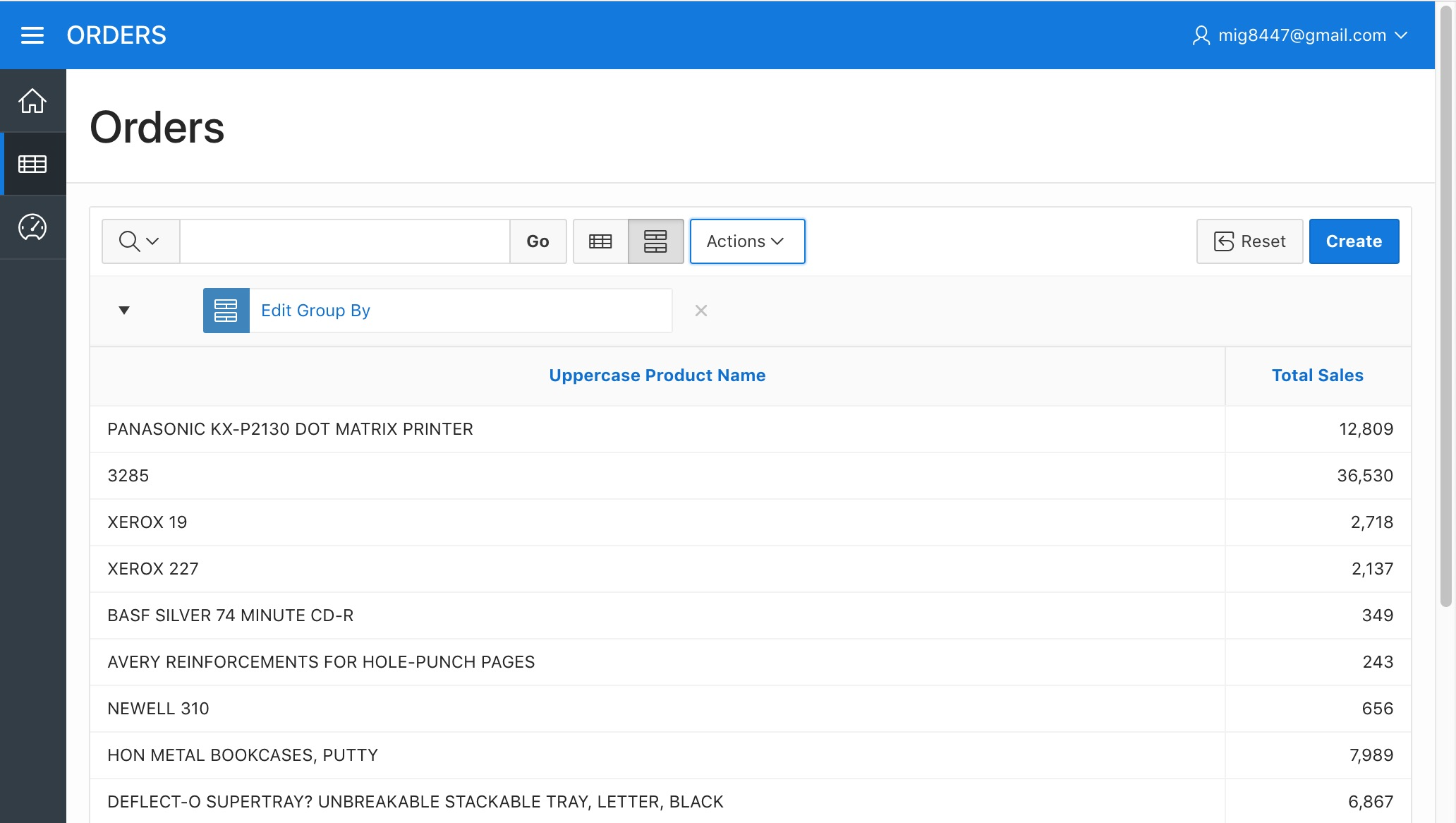
This generates a new report which has only two columns: The "Uppercase Product Name" and the "Total Sales"
Orders Report - Total Sales
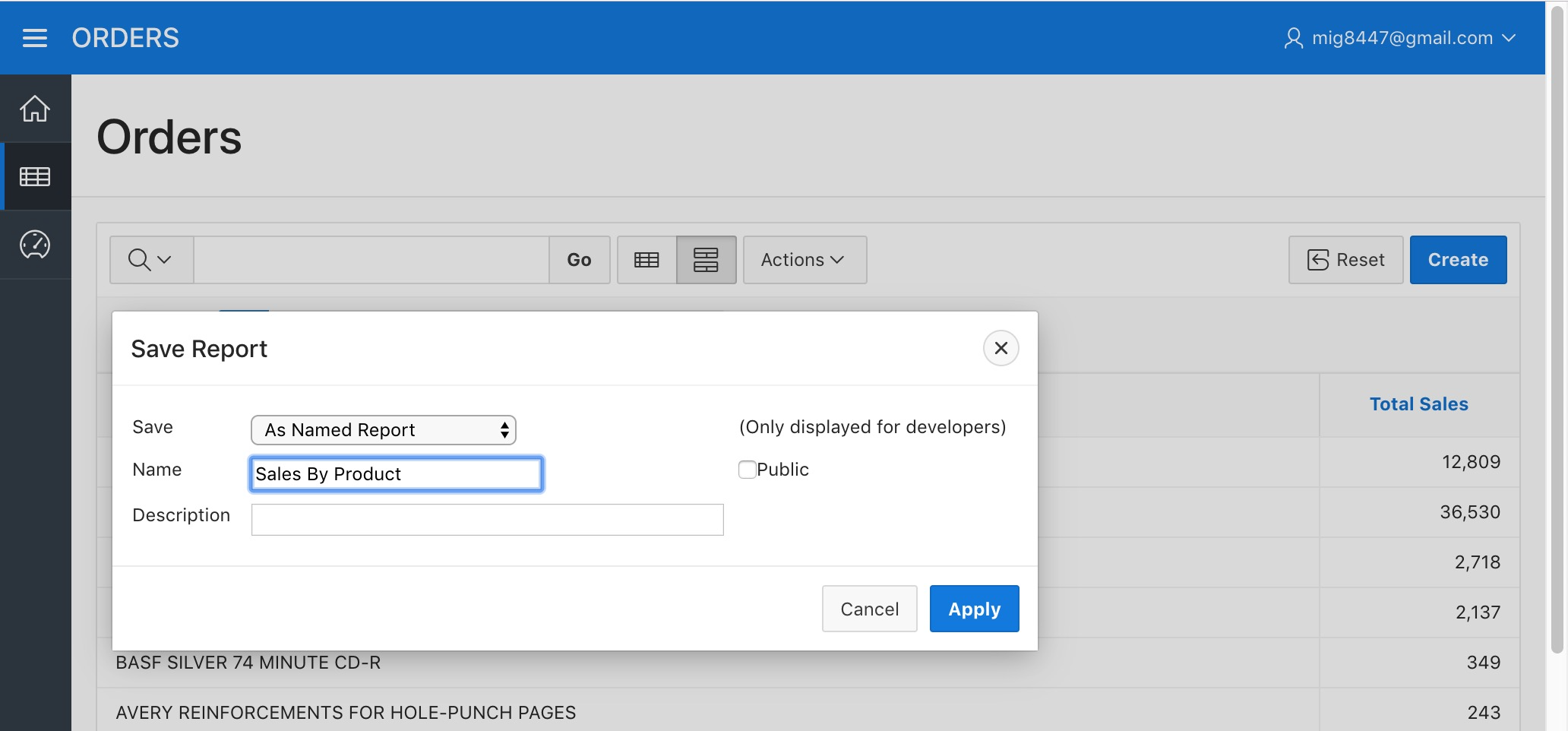
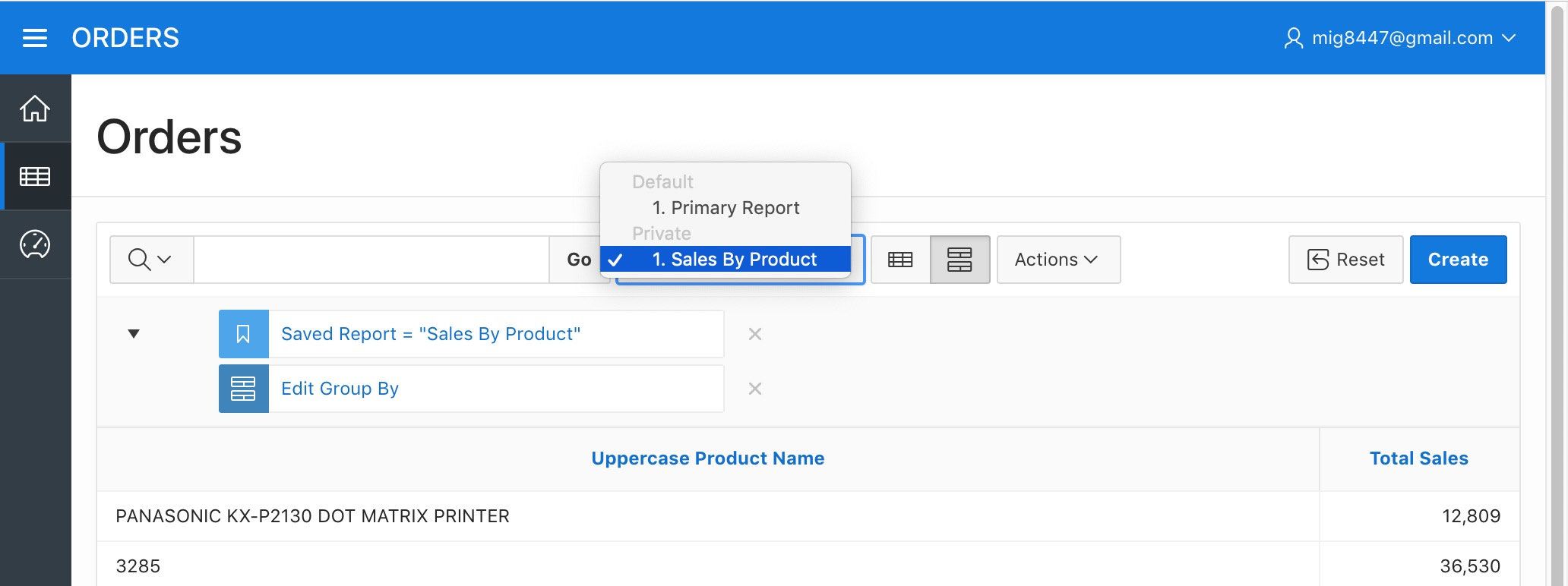
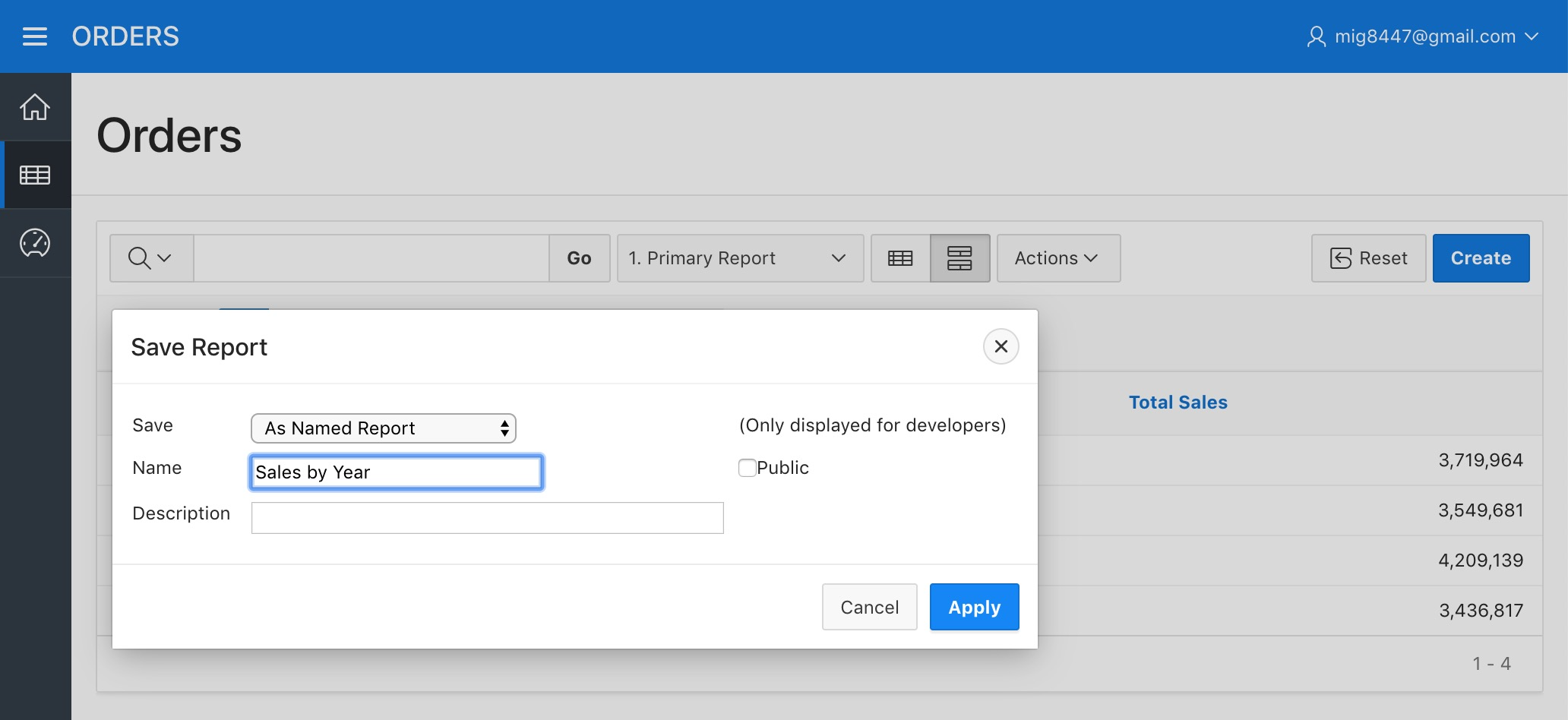
Now let's save this report to use it later. Hover the "Report" sub-menu from the "Actions" menu and select the "Save Report" option. Select "As Named Report" in the "Save" field and type "Sales By Product" as the "Name". Then click "Apply".
Orders Report - Save Named Report
The report is now saved. You will now see a select control next to the "Actions" menu. That new control will list all the reports we've saved. Notice that the new report is listed as "Private", this means that only developers will be able to see that saved report. We'll make it public later on.
Orders Report - Named Report Saved
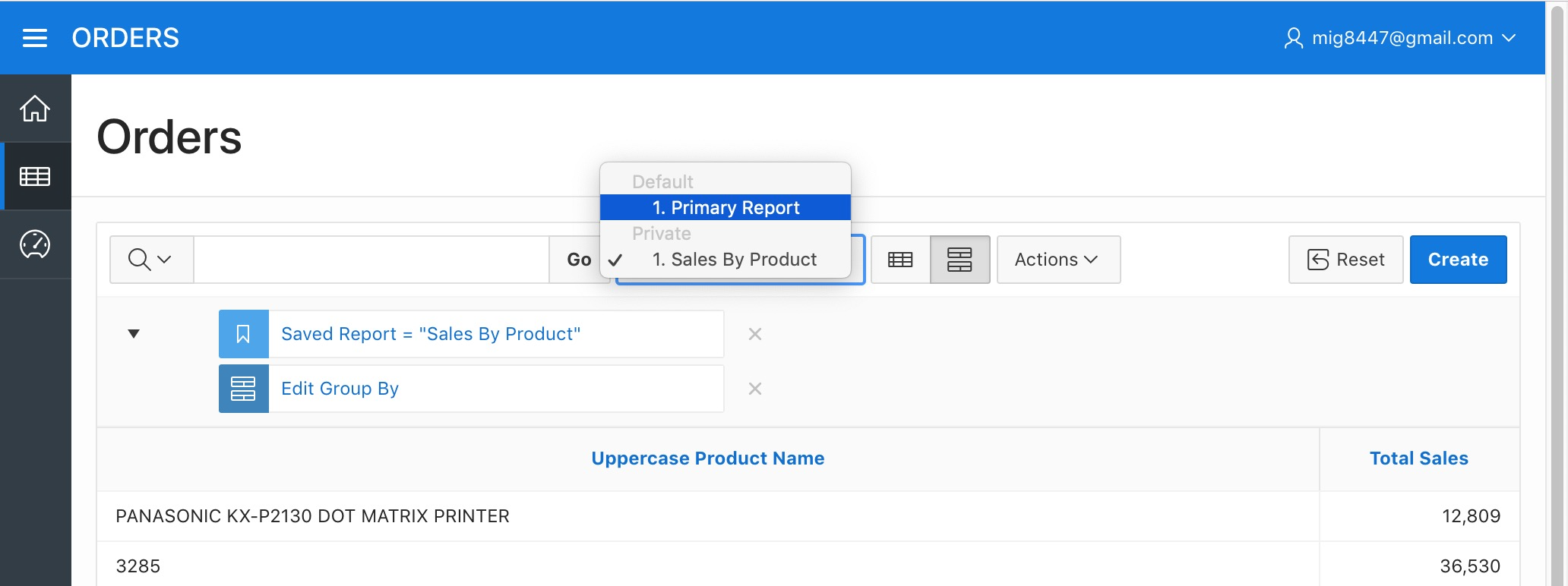
Now let's return to our "Primary Report"
Orders Report - Back to Primary Report
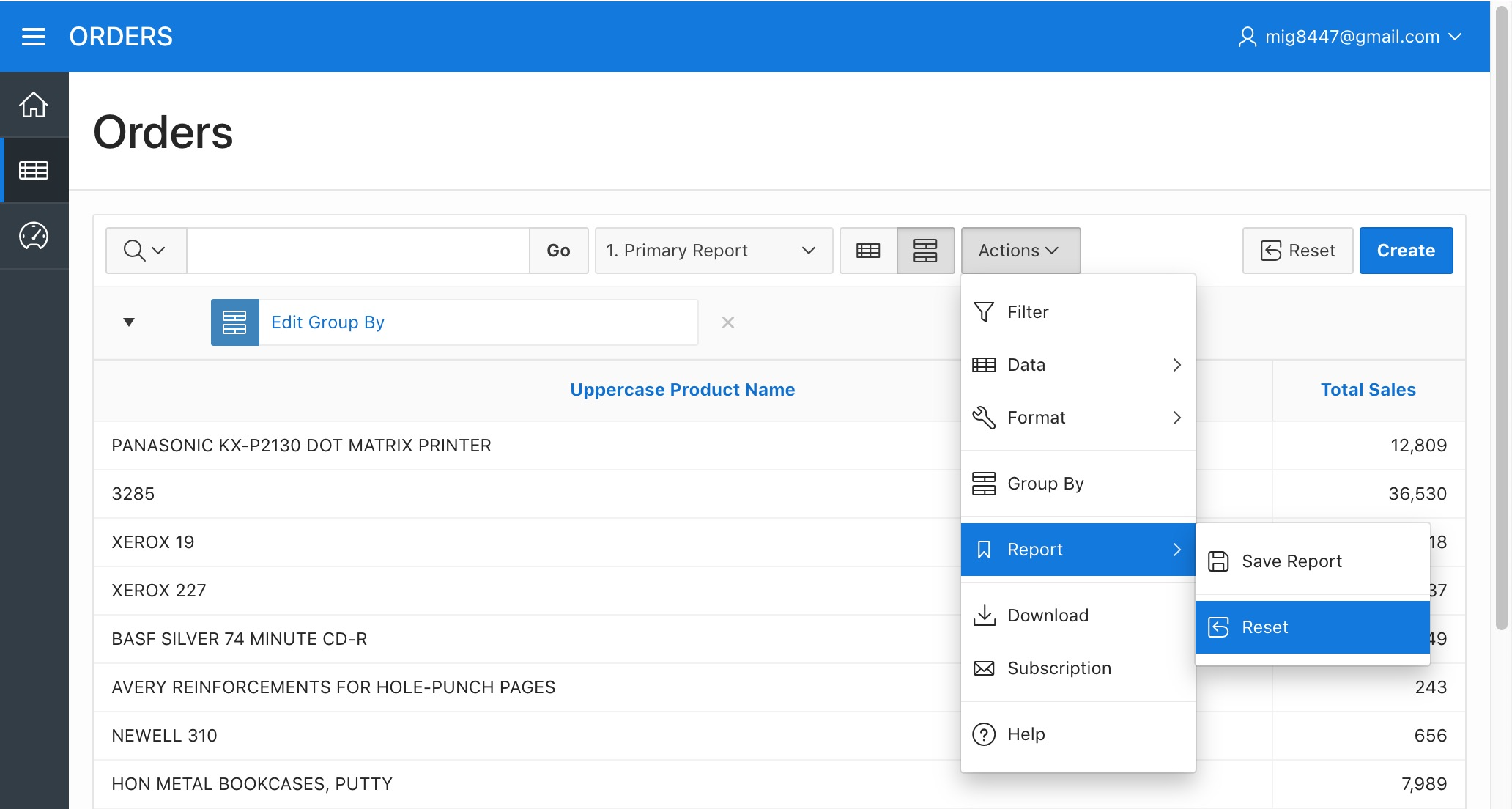
Select the "Reset" option from the sub-menu "Report" in the "Actions" menu to get it back to normal.
Orders Report - Reset
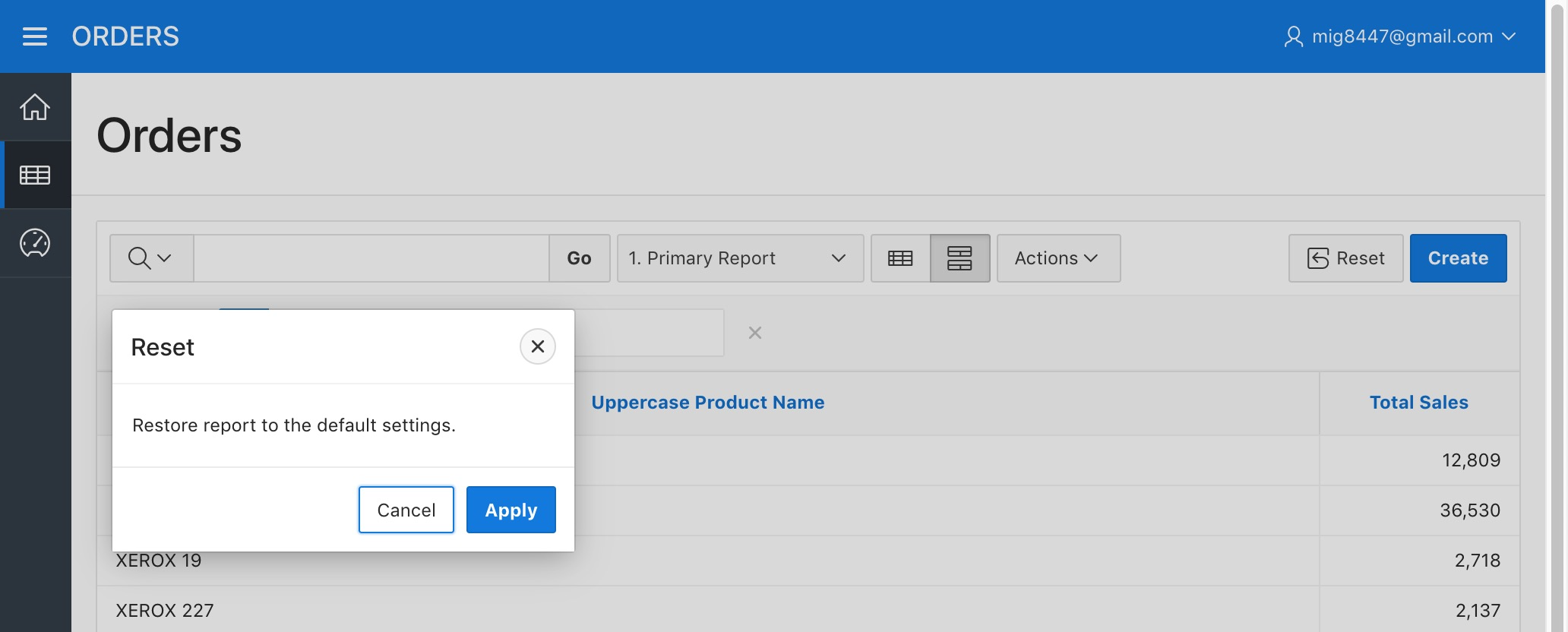
Click "Apply" on the dialog that appears. And it will get back to the saved report.
Orders Report - Reset
We'll now create another computed column for the year of the sale.
Data Computations - Obtaining the Full Year from a Date
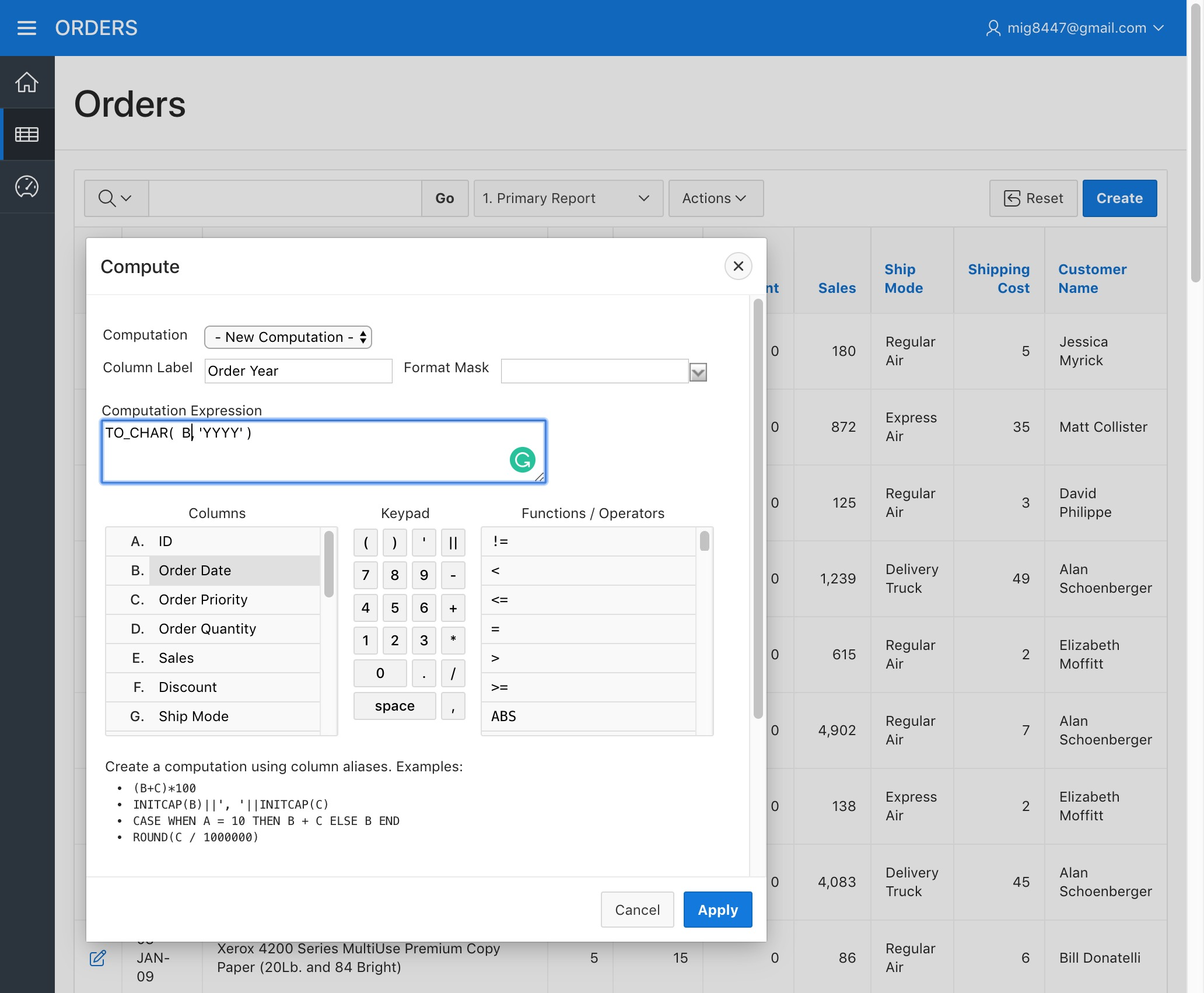
Click on the "Actions" menu once more and select the "Compute" option from the "Data" submenu. Type "Order Year" as the "Column Heading" and get the following on the "Computation Expression"
TO_CHAR( B, 'YYYY' )
Once more, make sure the letter B corresponds to the "Order Date" in the "Columns" list and if not, please change it for the corresponding letter in the "Computation Expression".
Orders Report - Compute Order Year
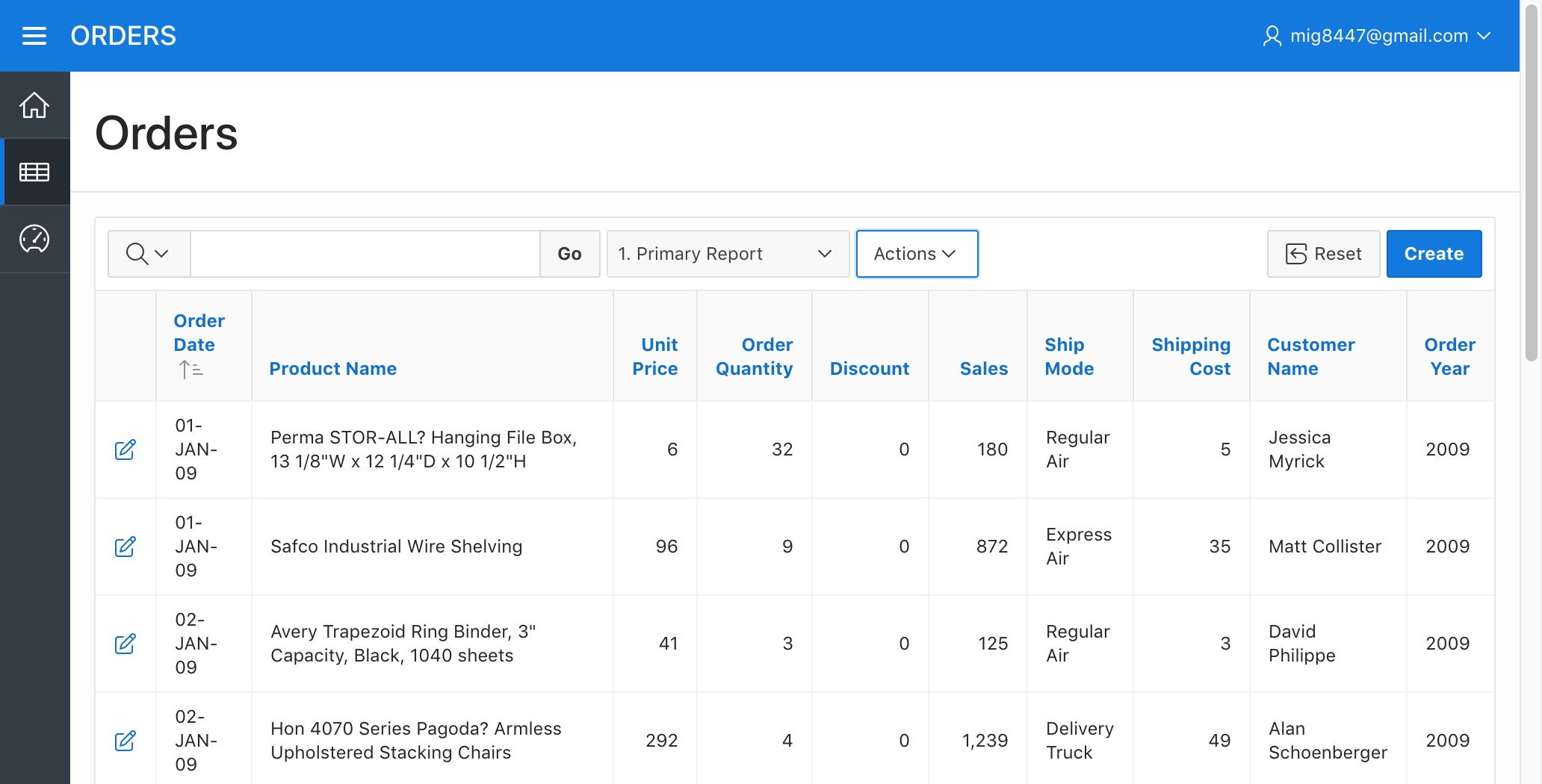
Click "Apply". A new column called "Order Year" now appears on the screen
Orders Report - Created Order Year Column
Grouping Data - Creating a "Sales By Year" Report
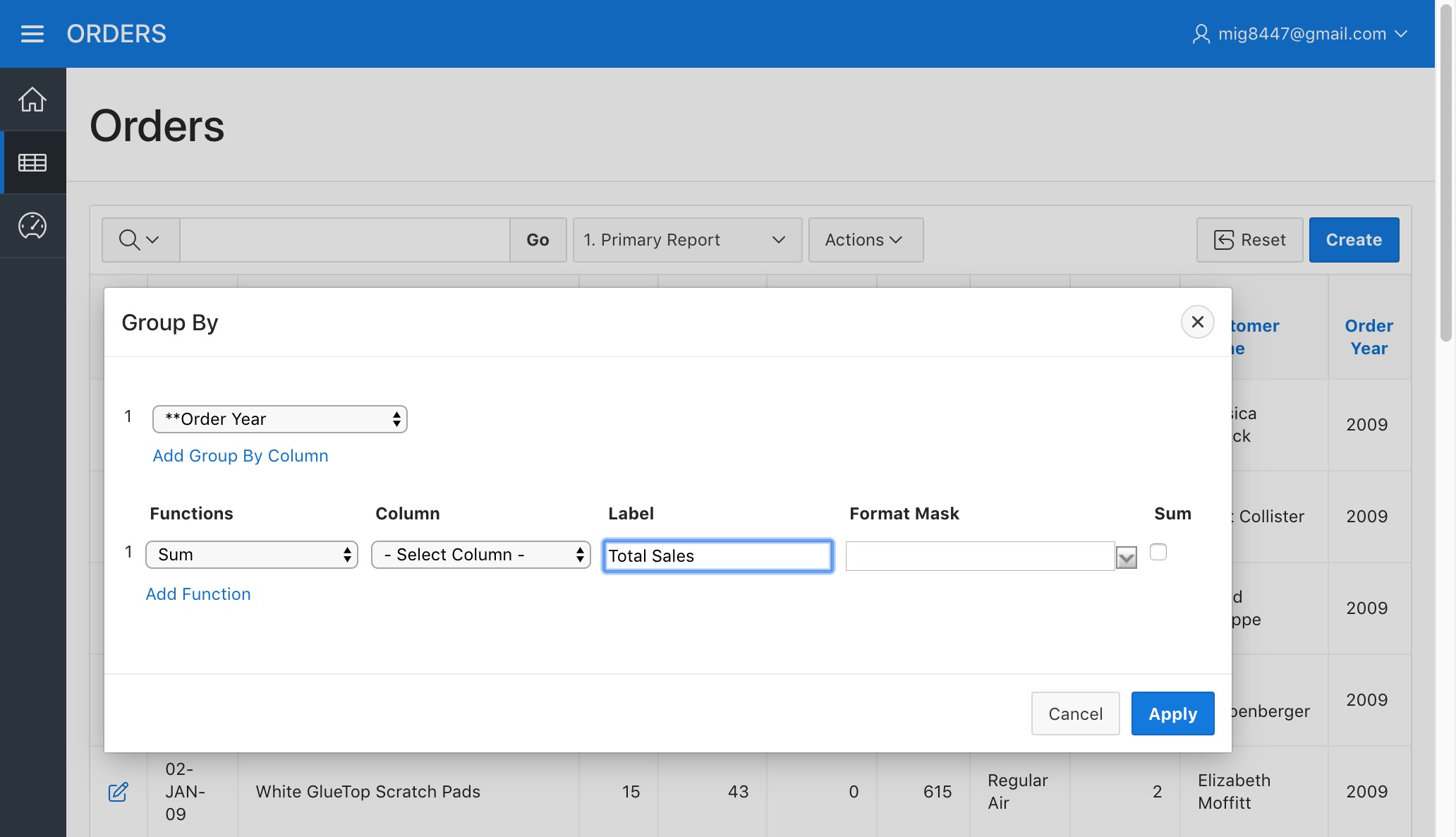
Back to the report, lets create a new "Group By" by selecting such option from the "Actions" menu. Select "**Order Year" as the "Group By Column", "Sum" as the "Function", "Sales" as the "Column", and "Total Sales" as the "Label".
Orders Report - Group By Order Year Column
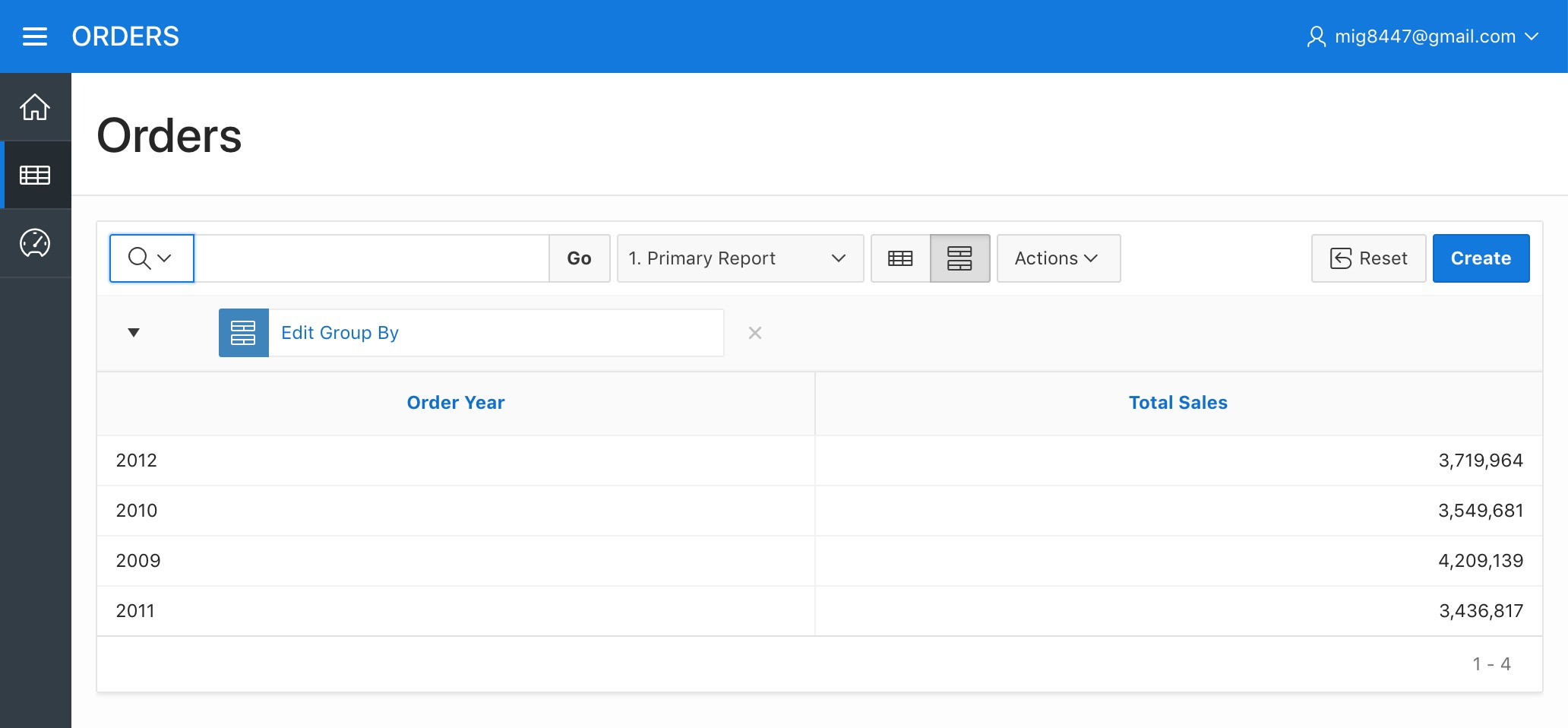
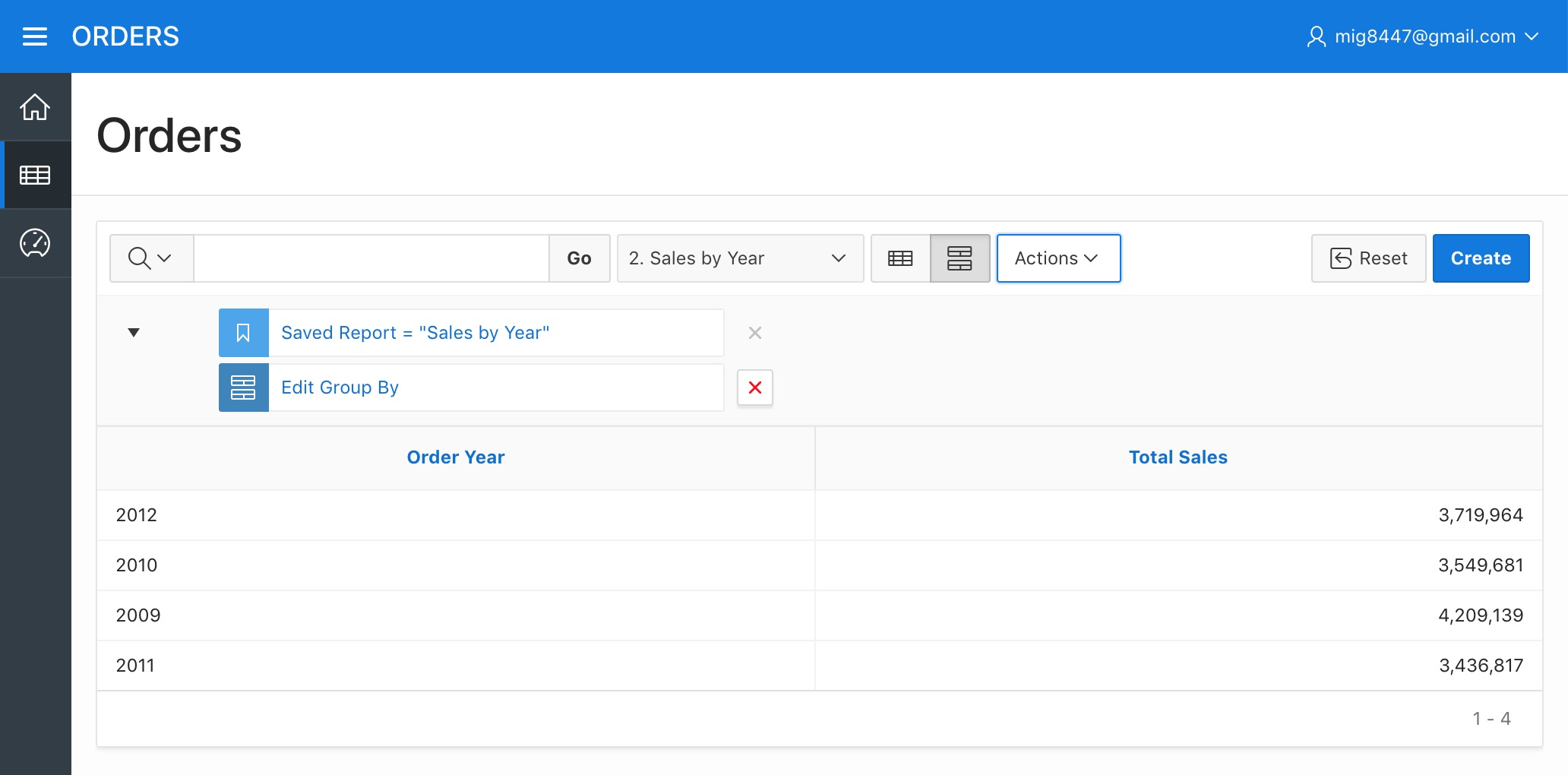
Click "Apply". We now have a "Sales by Year" report.
Orders Report - Sales by Year Report
Let's save it as a "Named Report". Name it "Sales by Year". Then click "Apply"
Orders Report - Sales by Year Report Save
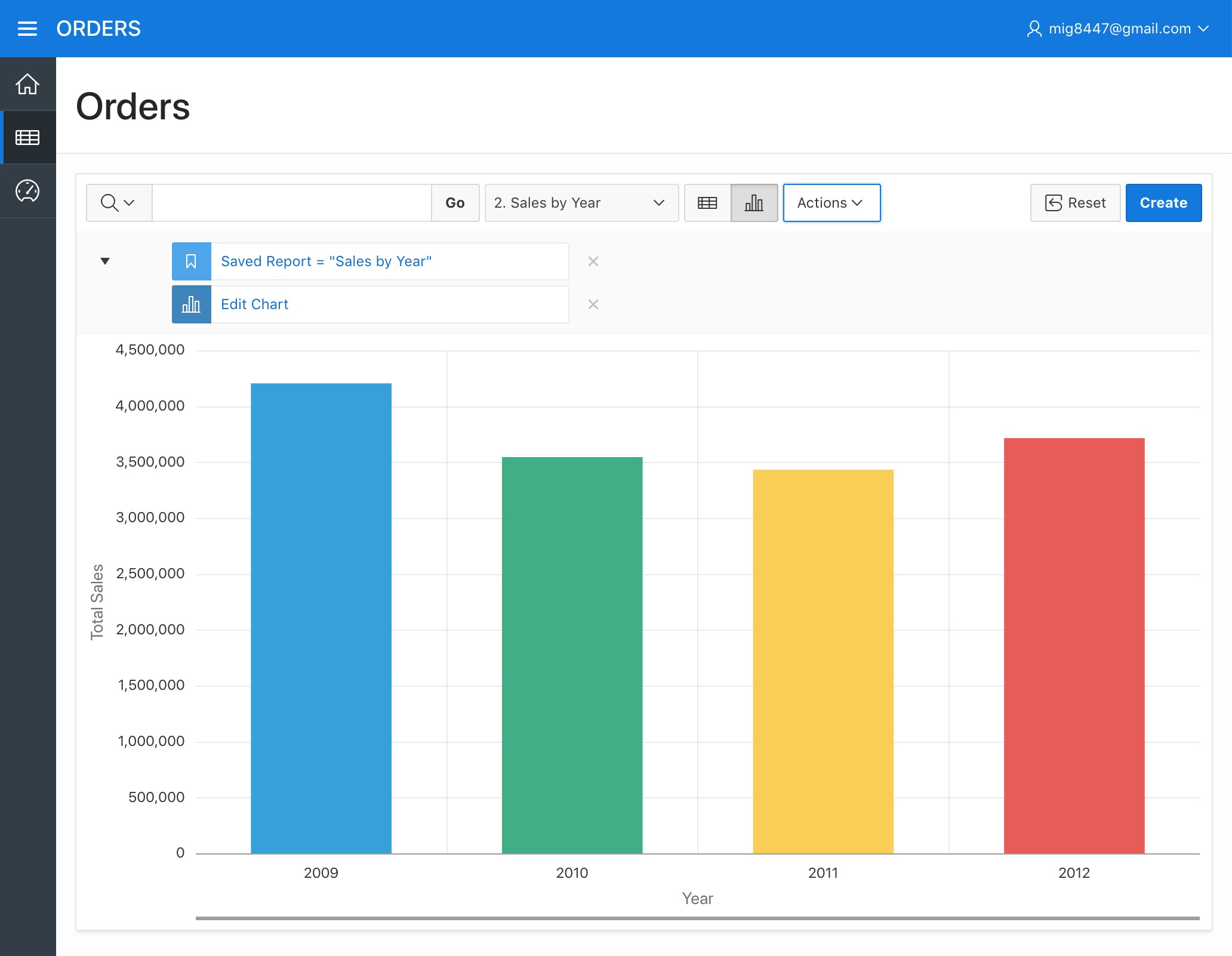
Now lets get a chart from the displayed data.
Charting Data - Creating a "Sales By Year" Chart
Click on the "X" button next to the "Edit Group By" element just below the search bar.
Orders Report - Remove Group By
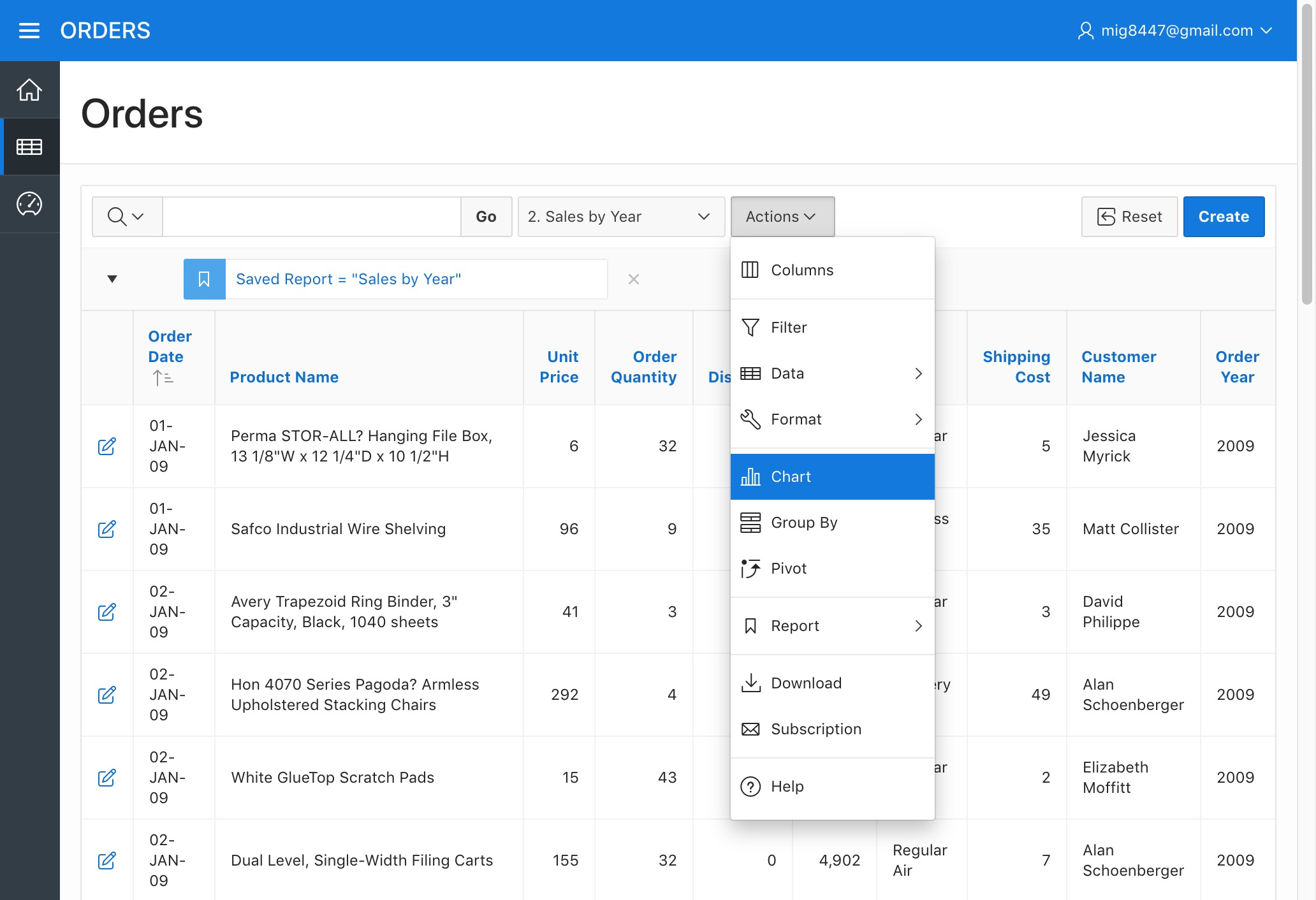
Select the "Chart" option from the "Actions" menu
Orders Report - Chart Menu
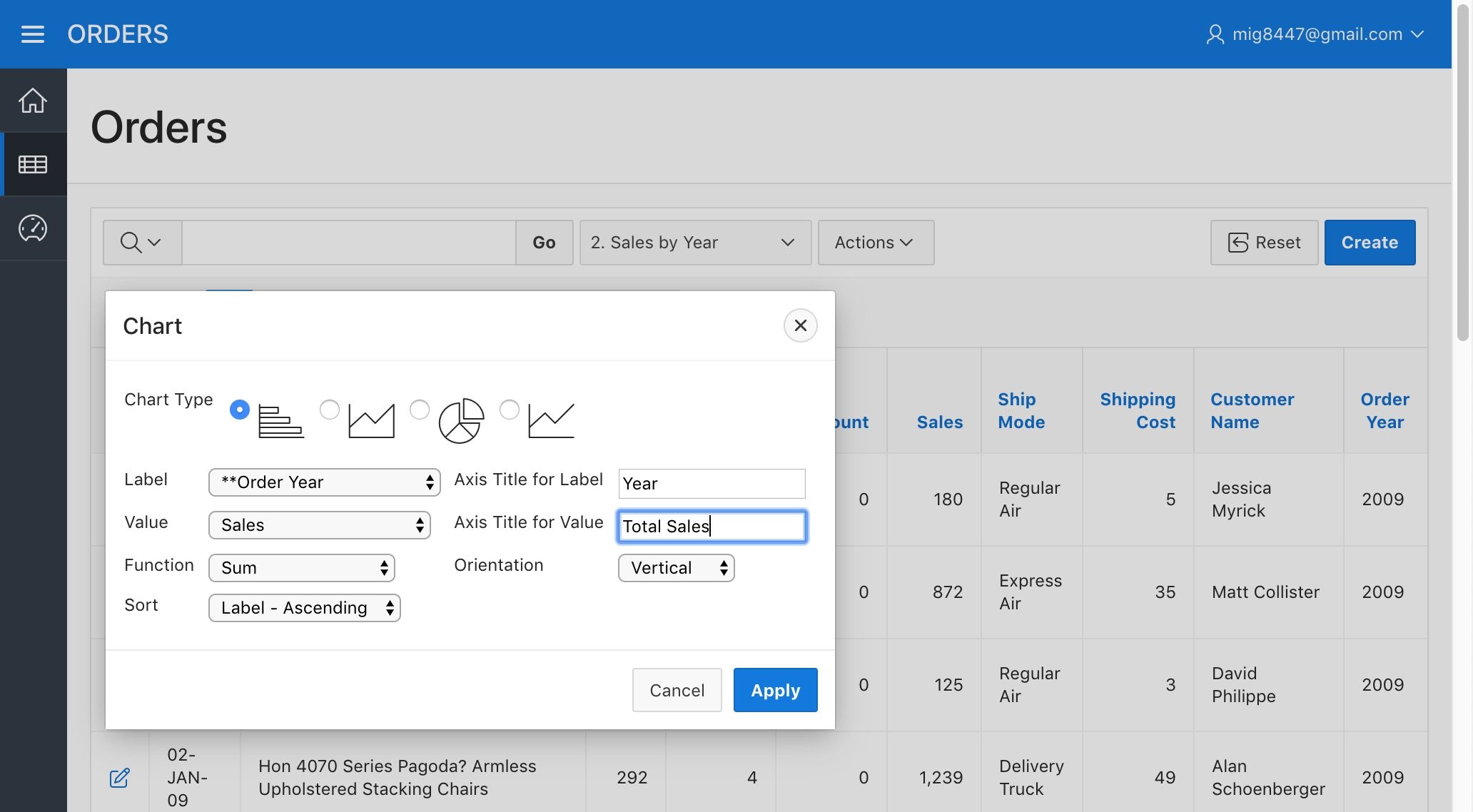
Now pick "**Order Year" as the "Label", "Sales" as "Value", "Sum" as the "Function", "Label - Ascending" as the "Sort", "Year" as the "Axis Title for Label", "Total Sales" as the "Axis Title for Value" and "Vertical" as the "Orientation". Click "Apply"
Orders Report - Sales By Year Chart
You now have a chart of "Sales by Year".
Orders Report - Sales By Year Chart Save
Save it as a named report and give it the name "Sales by Year (Chart)". Then click "Apply".
Named vs Default reports
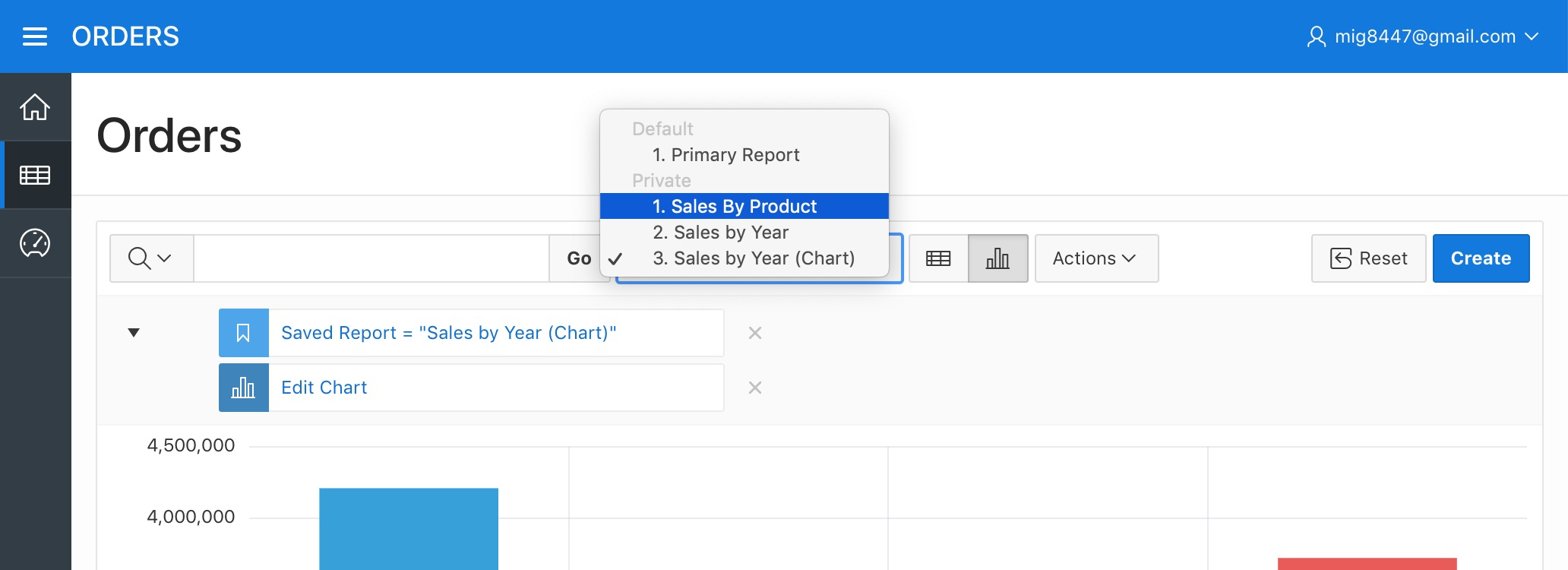
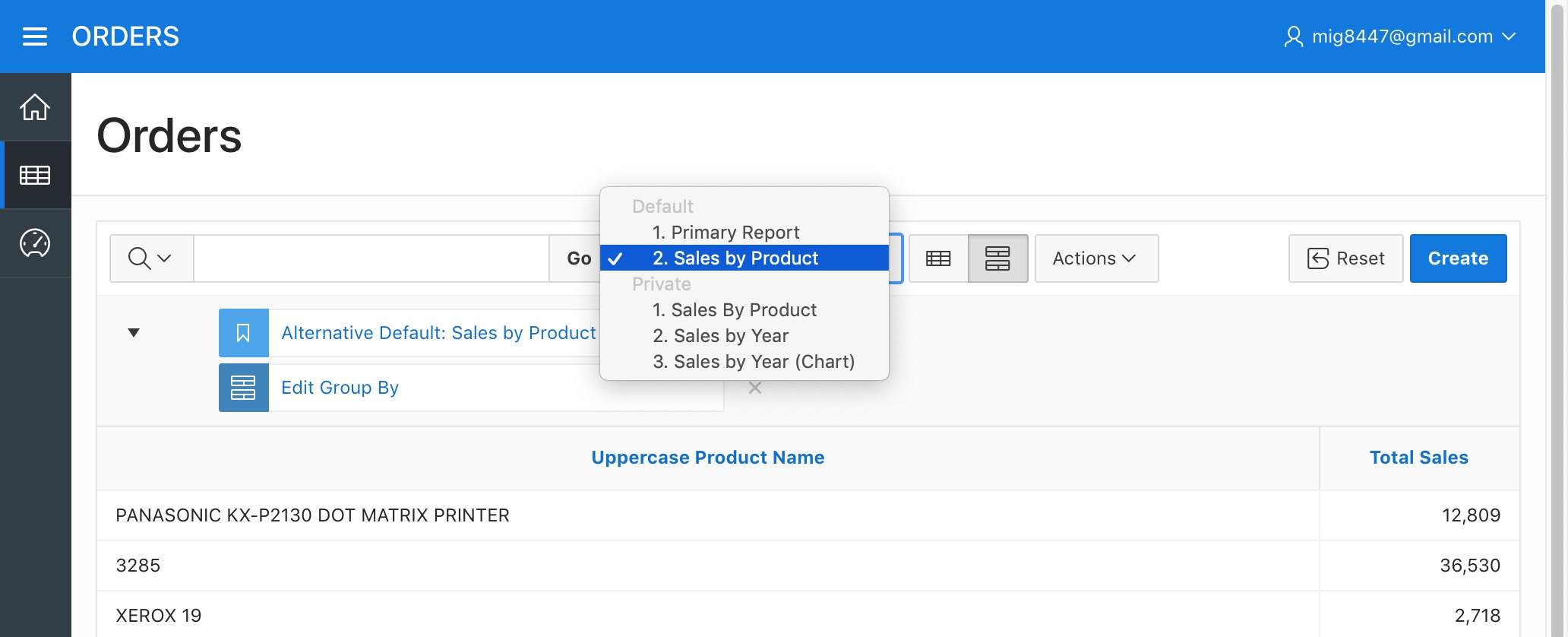
Notice you now have three Private reports. Private reports are only visible by their developer. This can be useful when creating or modifying a report without modifying the user's report list. Now that our reports are ready, let's make them available for the users. Select a report from the list next to the search bar.
Orders Report - Saved Reports
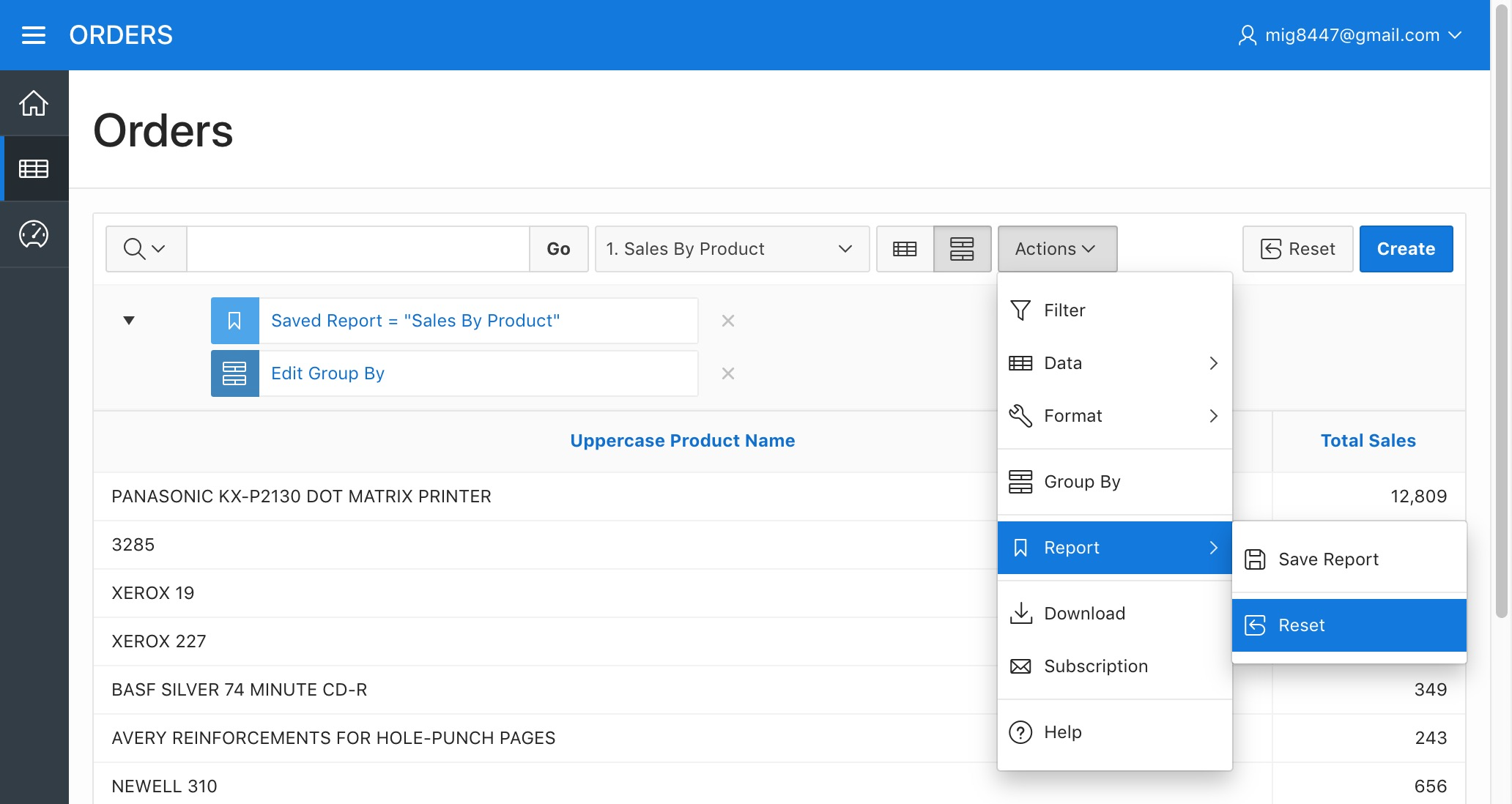
Select the "Reset" option from the "Report" sub-menu under the "Actions" menu. This will get the report back to its saved state.
Orders Report - Reset Report Step 1
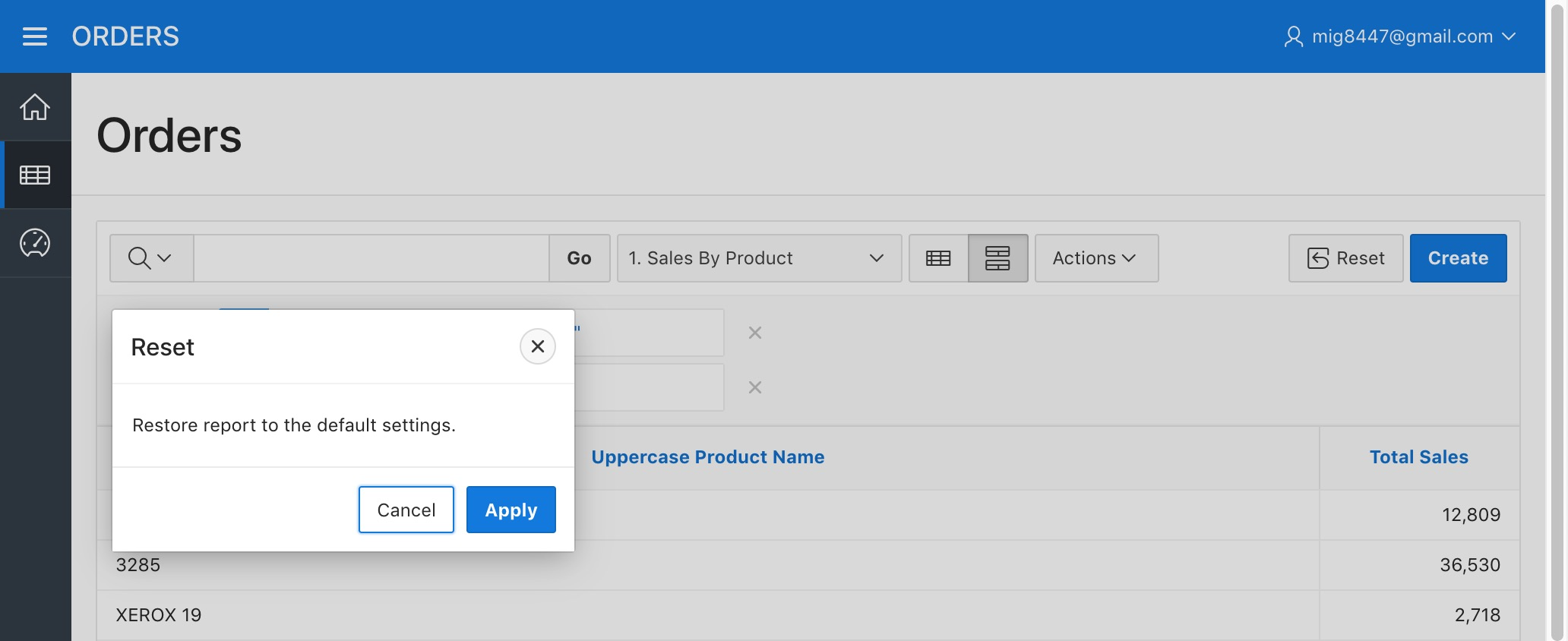
Confirm by clicking "Apply"
Orders Report - Reset Report Step 2
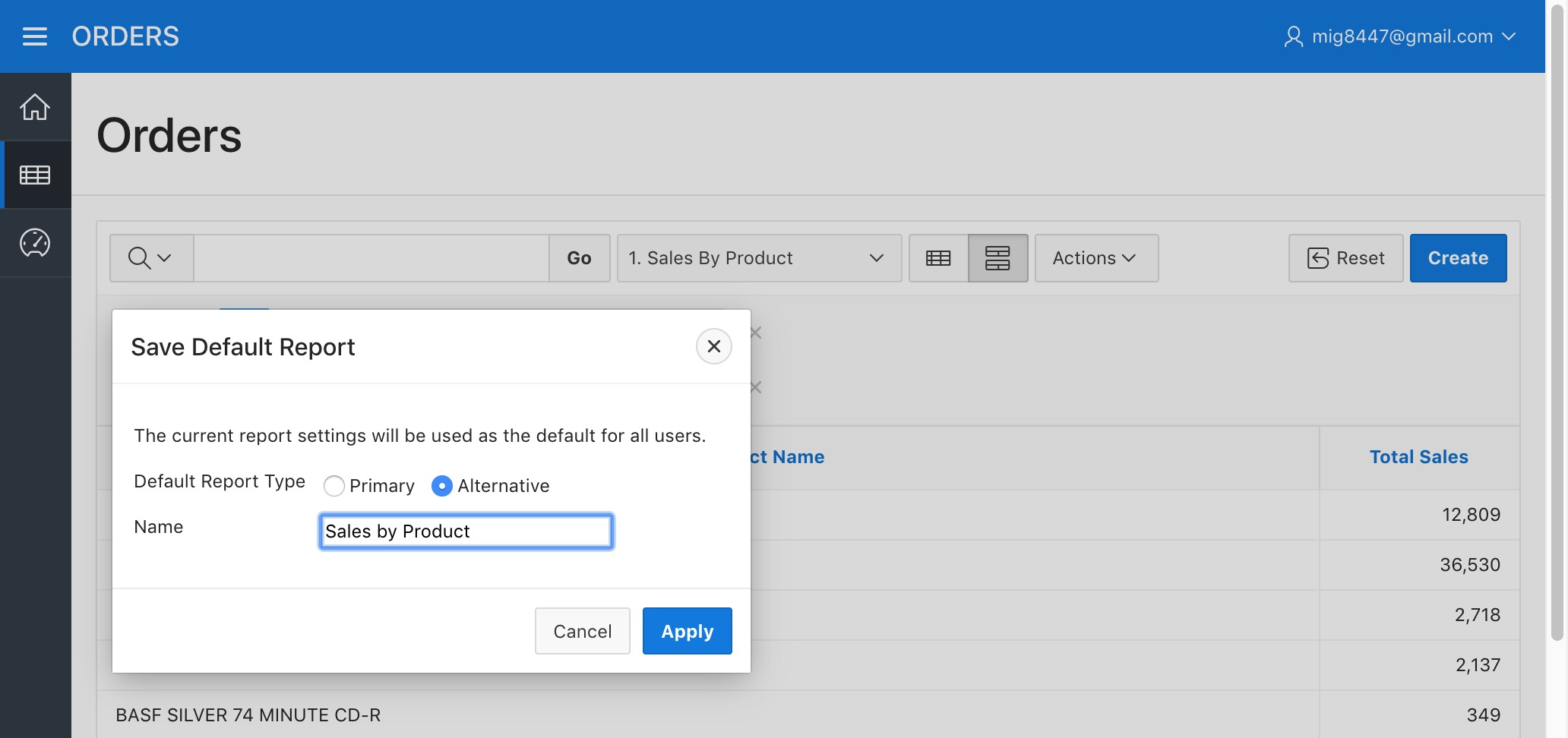
Click on the "Save Report" option from the "Report" sub-menu. Now, instead of saving it "As Named Report" we will save it "As Default Report Settings", this will make the report visible to the application users.
Orders Report - Save Alternative Report Step 1
Once the above dialog appears, select "Alternative" as the "Default Report Type" and enter the corresponding report name as the "Name", then click "Apply".
Orders Report - Save Alternative Report Step 2
Once saved, the report will appear under the "Default" category in the reports list next to the search bar and will be visible by the application users.
Orders Report - Public Report Saved
As a final note, it is worth mentioning that the application users can also make use of the report features depicted in this document, although when saving a report it will be visible only for the user that created it depending on the report's internal options.
]]>Miguel Sánchez VillafánOracle Application Express (APEX) - An Overview2019-02-24T15:42:31-06:002019-02-24T15:42:31-06:00https://mig8447.github.io/oracle/apex/2019/02/24/oracle-apex-an-overviewThis post intends to give an overview of Oracle Application Express (APEX) and its different components. This is the first in a series of posts about APEX
The views expressed here are my own and do not necessarily reflect the views of Oracle
Oracle APEX is an application development environment that enables its users to create secure, robust, responsive, and accessible applications fast. APEX is intended to create Data-driven applications, this is, applications that require data, and therefore a Database (Specifically an Oracle Database) to work.
Components
An APEX Instance is
Oracle Database (Any edition, including Express Edition, from version 11g onwards)
APEX Engine: A set of PL/SQL packages, functions and procedures that interact with the APEX Schema, this engine comprises of the public PL/SQL APIs exposed to customers as well as some private ones.
APEX Schema: Database Objects that store the APEX Instance metadata, the schema exposes several views, known as the APEX Views for the customers to query their workspace's or application's metadata.
Oracle REST Data Services (ORDS): APEX is normally run with the help of ORDS, a REST server which acts as a middleman between the Database and APEX and which provides it with REST capabilities
Browser: Any modern browser with which users will access APEX's UI and their Application's UI
Low Code
APEX's main advantage is its Low Code nature, which allows its users to develop and deploy applications with little or no code. Most of development is Wizard-driven, although deep customizations can be done to both the back-end and the front-end of the application, allowing to develop a Minimum Viable Product (MVP) within hours and to improve it over time.
No HTML, CSS, JS is required to implement a basic application
SQL, PL/SQL are the main languages you'll be using within APEX
Multi-tenancy
An APEX Instance is multi-tenant by nature, which means it can host a number of instance administrators in an isolated way by providing Workspaces for each of them work with. Workspaces in turn can host a multitude of individual users which can be either workspace administrators, developers or end users.
An APEX Instance structure can be simplified in the following way:
Workspaces: Isolated slices of the APEX Instance which are linked to one or several Database Schemas on which the applications' data can be stored.
Schemas: Database slices on which data can be stored. Typically a schema will contain tables, packages, and other database objects which cover the application's needs
Workspace Users: Either Administrators (Which can modify the workspace configuration), Developers (Can create or modify applications), End Users (Can use the workspace's applications) or any combination of the three.
Applications: A set of objects that interact with the associates workspace's database schemas to provide functionality for the end-users.
Pages: A set of objects related to a particular business requirement, like Register Users or Report on Monthly Sales
Regions: A section of the page containing objects with which the user can interact. Regions can be of different types, either Static, Dynamic, Report, Plug-ins, etc.
Items: Typically form inputs on which data must be provided by the application's end users. This data could then be merged, inserted, updated or manipulated in some way by the application's logic
Although more components could be added to this list, this is the main set of components am APEX developer mist be aware of.
Development Environment
APEX's development environment is divided into four main sections
SQL Workshop
The functionality provided by the SQL Workshop is mainly intended for data manipulation: Data Loading, Unloading (Exporting), Querying (Via SQL), Manipulation (Either SQL or PL/SQL) among other things. Developers will spend 30 to 40% of their time in this section.
Object Browser
The object browser is one of the most used tools in SQL Workshop. As its name states, it let's you browse the database objects found in the workspace's associated schemas, in here you can also edit the properties of those objects and even modify the code that comprises them.
SQL Commands
A place where you can execute SQL or PL/SQL statements directly into the Database. This tool provides a developer with not only the basics but also with tools for performance analysis, command history recall and even a personal command library on which a developer can save custom code snippets. Bare in mind that commands that exceed the 32KB limit in size cannot be executed using this tool but in turn using the SQL Scripts tool in the SQL Workshop.
SQL Scripts
This tool serves to save an execute SQL Scripts, specially scripts longer than 32KB in size. It provides the developer with a report containing the scripts recently uploaded/ran, and each of such scripts can be edited and run into the main workspace schema.
Utilities
This is not particularly a tool but a set of little tools that can be used for particular purposes.
Data Workshop
The Data Workshop is the most important Utility from the set, it allows users to import and export data into their workspace's schemas with ease. This tool can import files in different <CHARACTER> Separated Values formats, like Comma (CSV) or Tab (TSV) Separated values, and in a special XML format that preserves the table's structure metadata, the one I recommend when exporting data from an APEX Instance to another one.
Application Builder
The place where developers will be 60 to 70% of their time. The application builder contains several tools to import, export, list and edit applications, among other things.
Once within an application, you'll find several other application tools:
Supporting Objects: A tool to define scripts for installing/uninstalling or upgrading the application at hand.
Shared Components: A management tool for components shared among the application. These components include Static Files (Like images, JavaScript files, CSS files, among others), Authentication Schemas (Which define specific conditions to let users into the application), Authorization Schemas (Which define conditions as to what a particular group of users can or can't see)
The Page Designer (Page Editing Tool): Whenever you click on a particular application page, you are presented with a set of four panels, one, at the left (The Component Tree Panel), one at the right (The Attribute Editing Panel), one at the bottom (The Available Components Panel) and one in the middle (The Layout Editor)
Team Development
This section is usually underutilized, but it offers very powerful project management tools. You can log bugs, enhancements and even user feedback can get logged in here. You can manage application's development milestones and collect the different enhancements you want into a particular milestone, define deadlines and much more.
Application Gallery
A place from which you can install pre-made applications, written by the APEX developers themselves to serve to particular purposes. These applications can be installed to be run or unlocked for development, and can even serve as examples on how to do a particular thing.
]]>Miguel Sánchez VillafánThe Branch-When-Needed extended branching system2018-11-15T09:01:26-06:002018-11-15T09:01:26-06:00https://mig8447.github.io/scm/svn/2018/11/15/svn-branch-when-needed-extended-branching-systemThere are many branching systems to follow out there, some of which can be found within the SVN Best Practices article from Apache. The following is a slight modification to such article's Branch-When-Needed system.
I came up with this after trying several other systems and finding ourselves with a broken trunk or with the merging hell. Once we implemented this system those things went away and today my team is still using it to manage our projects' source on SVN.
Rules
Users commit their day-to-day work on /branches/development abiding to the following rules:
Work committed to /branches/development can be occasionally broken so that users can sabe their work even when it's not yet complete without worrying about loosing their local work
A single commit (change set) must not be so large so as to discourage peer-review and should include a commit message with a clear description of the changes performed
If the change set(s) required to complete a particular feature or fix are too big and could potentially break development, disrupting other users' day to day work, then a branch should be created and small/reviewable change sets should be committed to such branch, which must also be kept in sync with /branches/development so that merging the branch when the feature/fix is complete causes the least possible pain
Once work in development is stable and passes the tests, /branches/development should be merged into /trunk
/trunk must compile and pass tests at all times. Committers who violate this rule must fix trunk at their earliest and backport their changes to /branches/development once the problem is fixed
Tagging /trunk in a per-release basis is mandatory
Pros
/trunk is guaranteed to be stable at all times
User's daily workflow is kept seamless within /branches/development
Cons
Merging from /branches/development to /trunk may become a hassle under rare circumstances but it's worth the peace of mind that committing everything at the end of the day and going home brings
]]>Miguel Sánchez VillafánObtaining the RPM sources from the spec file2018-10-15T13:00:07-05:002018-10-15T13:00:07-05:00https://mig8447.github.io/linux/rpm/2018/10/15/obtaining-the-rpm-sources-from-the-spec-fileIn this post, I'll talk about how to programatically obtain the source list from the an RPM specification (spec) file and what's the usecase for it
TL;DR
To obtain the source files from the spec file execute the following:
So if I already have the spec file, and I can read it, Why do I need this?
Fair question, but, what would you do if you want to have a dynamic spec or more so, a dynamic build script that reads the sources from the spec and downloads them or even builds them with some scripts you have available.
In summary: automation is the why.
Of course you could have something like:
grep-iE'Source[0-9]+:' <SPEC_FILE_PATH>
to do it, but what if your source strings are built within the spec given certain macros?
With the above grep command you'd get the macros that comprise the sources, and you'd have to parse the file to find the right definition for the source file.
Pre-requisites
In order to do this, you'd need an RPM spec file of course and you'd also need to have the spectool program, which is shipped within the rpmdevtools package, you can check if such package is installed by running:
rpm -q rpmdevtools
You can also check if you have spectool installed by executing either
which spectool
or
command-v spectool
If you don't have the program, nor the package installed , try to install the package by issuing the dollowing command (In a Red Hat based distribution)
sudo yum install rpmdevtools
The solution
The spectool's purpose is mainly to download the sources needed by a specfile (If they're URLs), but it can also be used to our advantage by providing the flags:
Flag
Purpose
-l
List the sources/patches
-S
List only the sources
So our final command will end up looking like:
spectool -l-S <SPEC_FILE_PATH>
]]>Miguel Sánchez VillafánChecking if a Bash variable is unset2018-07-25T23:37:16-05:002018-07-25T23:37:16-05:00https://mig8447.github.io/linux/bash/2018/07/25/checking-if-a-bash-variable-is-unsetThis post explores the differences between a null (empty) variable and an unset variable in Bash. It also contains a snippet to check whether a variable is set or not and gives you a use case so you can give it a real-world application.
TL;DR
Check if unset
if [[ -z "${variable+set}" ]]; then
echo 'unset';
fi
Check if set
if [[ -n "${variable+set}" ]]; then
echo 'set';
fi
How NOT to do it
Wrong solution number 1
You're doing it wrong
if [[ -z "$variable" ]]; then
echo 'unset';
fi
Why?
According to the conditional expressions documentation, the -z string will "return" true if the length of the passed string (The expansion of "$variable" in our case) is zero. Lets analyze that statement for a second… What does "$variable" expands to if it is unset? Unless you have Bash's -u (For which I will dedicate another post) option set, the result of such expansion will be an empty string (Or a null value in Bash slang). What did -z "returned" when the length of the passed string was zero? True!. This means that -z doing its job just fine but it also means that it will "return" true even if the variable is set to an empty value.
Wrong solution number 2
Almost! but not quite
if [[ -z "${variable:+set}" ]]; then
echo 'unset';
fi
${parameter:+word}
If parameter is null or unset, nothing is substituted, otherwise the expansion of word is substituted.
So yes, "${variable:+set}" will expand to nothing (aka an empty string, aka a null value) if parameter is unset, But it will also do it if the parameter is null!, which defeats our purpose once again.
A null variable vs an unset variable
So why all of this? There's a fundamental thing to understand here, a null (empty) variable is NOT the same as an unset variable. The difference is basically that the empty variable is part of the environment on which I'm running my commands and an unset variable is not.
For non-bash "speakers" a null variable is the equivalent of a variable set to an empty string in any other language, while an unset variable would be the equivalent of not declaring the variable at all. Who can tell me what happens in Java if a variable I'm using somewhere is not declared? The code won't compile!. The world isn't that black or white with Bash though (Again, except if you set the -u option in Bash), bash will gladly compare an unset variable to whatever you want, Why is it a problem? Besides what I would explain in the -u post, because sometimes you want to have the ability to discern if a user did not set a variable or if it was set to an empty value on purpose, in our Java example this would be comparable to have the ability to discern between a null object and an "empty" one, which is IMHO a fundamental ability to have.
Look ma!, no colon
So Wrong solution number 2 almost had it, it was making use of parameter expansion, it was making use of the -z operator, but it fell short in a small-but-very-important-thing: The colon :. If only the developer who wrote it had read a couple of lines above the parameter expansion definitions he would have noticed the following:
When not performing substring expansion, using the form described below (e.g., ‘:-’), Bash tests for a parameter that is unset or null. Omitting the colon results in a test only for a parameter that is unset. Put another way, if the colon is included, the operator tests for both parameter’s existence and that its value is not null; if the colon is omitted, the operator tests only for existence.
[…] if the colon is omitted, the operator tests only for existence.
Tada :tada:!, so the solution, is to remove the colon : from the Wrong solution number 2 code, which leaves us with:
if [[ -z "${variable+set}" ]]; then
echo 'unset';
fi
Question for you: Why do we have to double quote the parameter expansion? Comment in the box below, if the answer is in the first 50 comments, I'll put the answer and the name of the commenter in an edit to this post, if the answer is not there, I'll still be putting the answer in an edit. Until then… happy Bash-ing
Use case
One of the most comon usecases for this is to see if a positional parameter in a script was set or intentionally left empty. If we're looping trough our parameters, we would want to stop at the last parameter, not at the first null one.
Glossary
TL;DR: Too Long; Didn't Read (See https://blog.oxforddictionaries.com/august-2013-update/) aka: Also Known As IMHO: In My Humble Opinion
]]>Miguel Sánchez VillafánHello World!2018-07-23T18:53:43-05:002018-07-23T18:53:43-05:00https://mig8447.github.io/blog/2018/07/23/hello-worldAs a tradition to developers this is the first post and a welcome message to whomever happens to read this.]]>Miguel Sánchez Villafán